

4 January 2016
Recently I've come across using XML parsing with web scraping and combining many XML tables. Because of its syntax, I wanted to outline some basic rules about XML and how to work with XML files within Alteryx.XML files are different from flat columnar tables (the ones we're used to!) because instead of headers and rows, the data is nested within tags, where the field headers are identified for every record with <> brackets. Below is the example from Reading XML by Alteryx where the same data is presented as a columnar table and the other in XML. Because of its nested nature, it needs a bit of digging/examining the original data to figure out which tags to target and parse.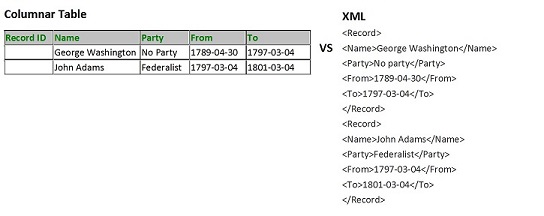 Example 1: Parsing from 1 XML fileLet's go through one recent example I was working on for a client - parsing clinical trial data from XML files. Let's say I wanted to 2 pieces of information - the name of the trial and when did it start. I like to take a look at the XML file to see where is the information located so I can figure out the best way to parse it.I've opened the file in notepad++ and highlighted the tags which show which pieces of data I am looking for. Note that the root element in this file is 'clinical study', and it just so happens that <brief_title> and <start _date> are child values.
Example 1: Parsing from 1 XML fileLet's go through one recent example I was working on for a client - parsing clinical trial data from XML files. Let's say I wanted to 2 pieces of information - the name of the trial and when did it start. I like to take a look at the XML file to see where is the information located so I can figure out the best way to parse it.I've opened the file in notepad++ and highlighted the tags which show which pieces of data I am looking for. Note that the root element in this file is 'clinical study', and it just so happens that <brief_title> and <start _date> are child values.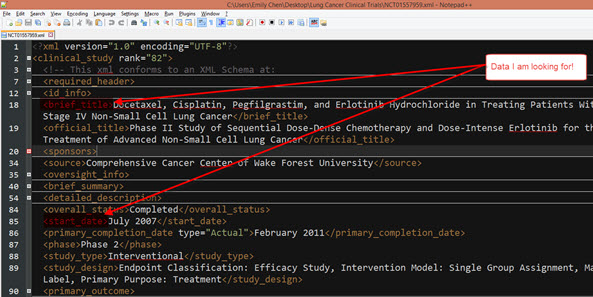 What happens when I select this file in Alteryx's input tool?Alteryx's default settings is to pick up only 1 set of the file's child values, so there's a lot of information not yet coming through.Result in Alteryx picks up the <condition> tag/element in the XML file.
What happens when I select this file in Alteryx's input tool?Alteryx's default settings is to pick up only 1 set of the file's child values, so there's a lot of information not yet coming through.Result in Alteryx picks up the <condition> tag/element in the XML file.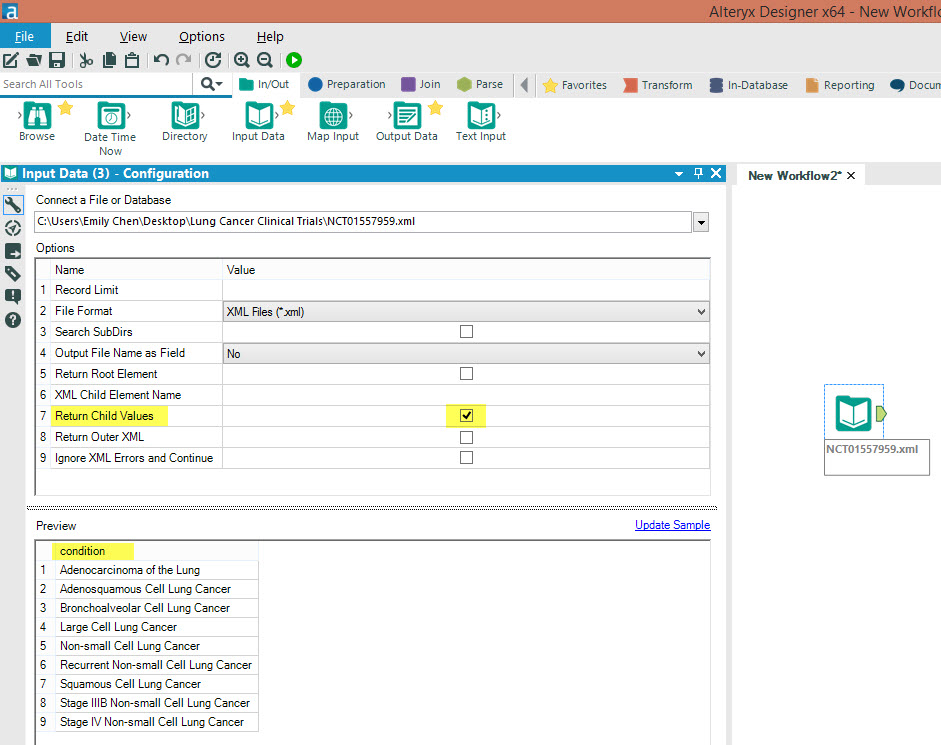 I can bring the information we are trying to parse into Alteryx by selecting 'Return Root Element' and 'Return Child Values' as the information we are looking for is only 1 layer beneath the Root Element.
I can bring the information we are trying to parse into Alteryx by selecting 'Return Root Element' and 'Return Child Values' as the information we are looking for is only 1 layer beneath the Root Element.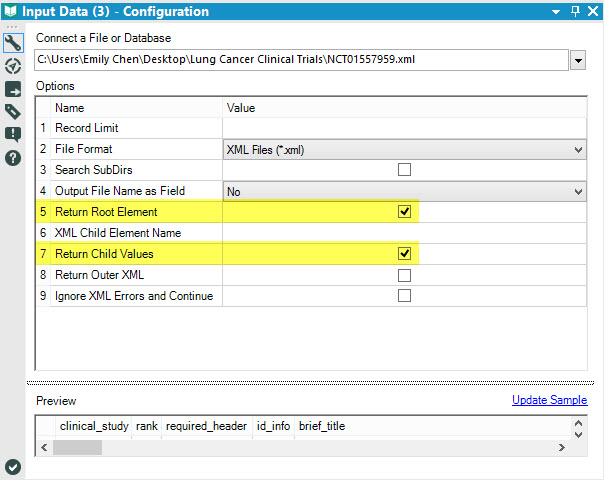 Simply add a select tool for the fields we wanted to parse and voila!
Simply add a select tool for the fields we wanted to parse and voila!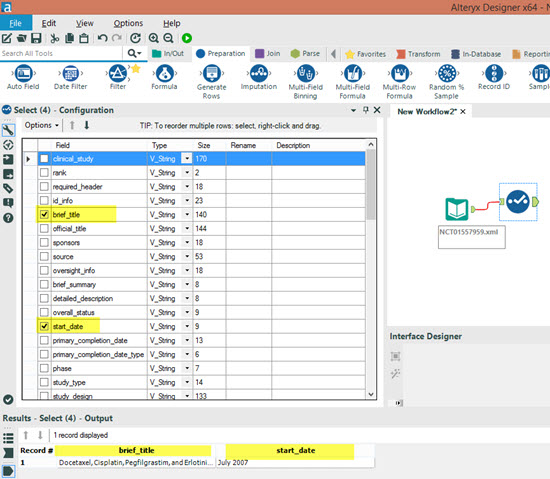 But what if I want to parse data that is nested deeper within the XML file?Like if you wanted to find who sponsored the clinical trial?
But what if I want to parse data that is nested deeper within the XML file?Like if you wanted to find who sponsored the clinical trial?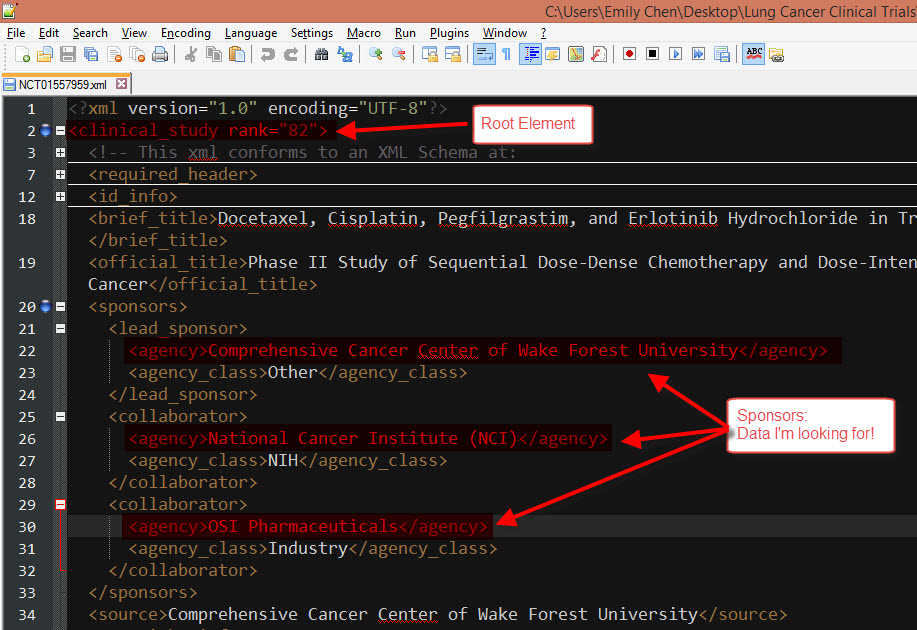 The data is nested within the <agency> tags, so its not a child value of the root element. This is where can use the Outer XML configuration to bring in all XML tags within the root element. From there, we can parse out the <agency> tags with the ..
The data is nested within the <agency> tags, so its not a child value of the root element. This is where can use the Outer XML configuration to bring in all XML tags within the root element. From there, we can parse out the <agency> tags with the .. XML Parse Tool!Simply select 'Return Root Element' and 'Return Outer XML' in the input tool so Alteryx can identify both the root element and its respective nested tags.
XML Parse Tool!Simply select 'Return Root Element' and 'Return Outer XML' in the input tool so Alteryx can identify both the root element and its respective nested tags.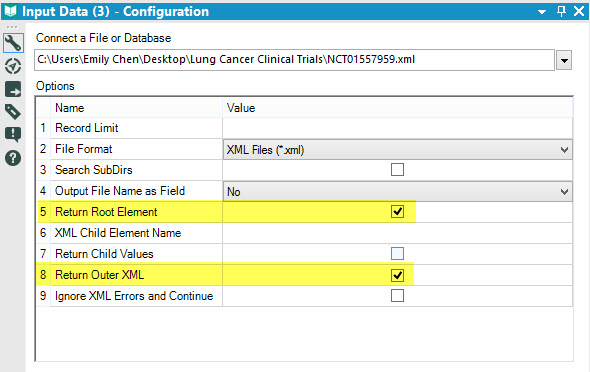 Then add the XML Parse tool and configure the tool to look for the <agency> tag within the new field 'clinical_study_OuterXML'.
Then add the XML Parse tool and configure the tool to look for the <agency> tag within the new field 'clinical_study_OuterXML'.
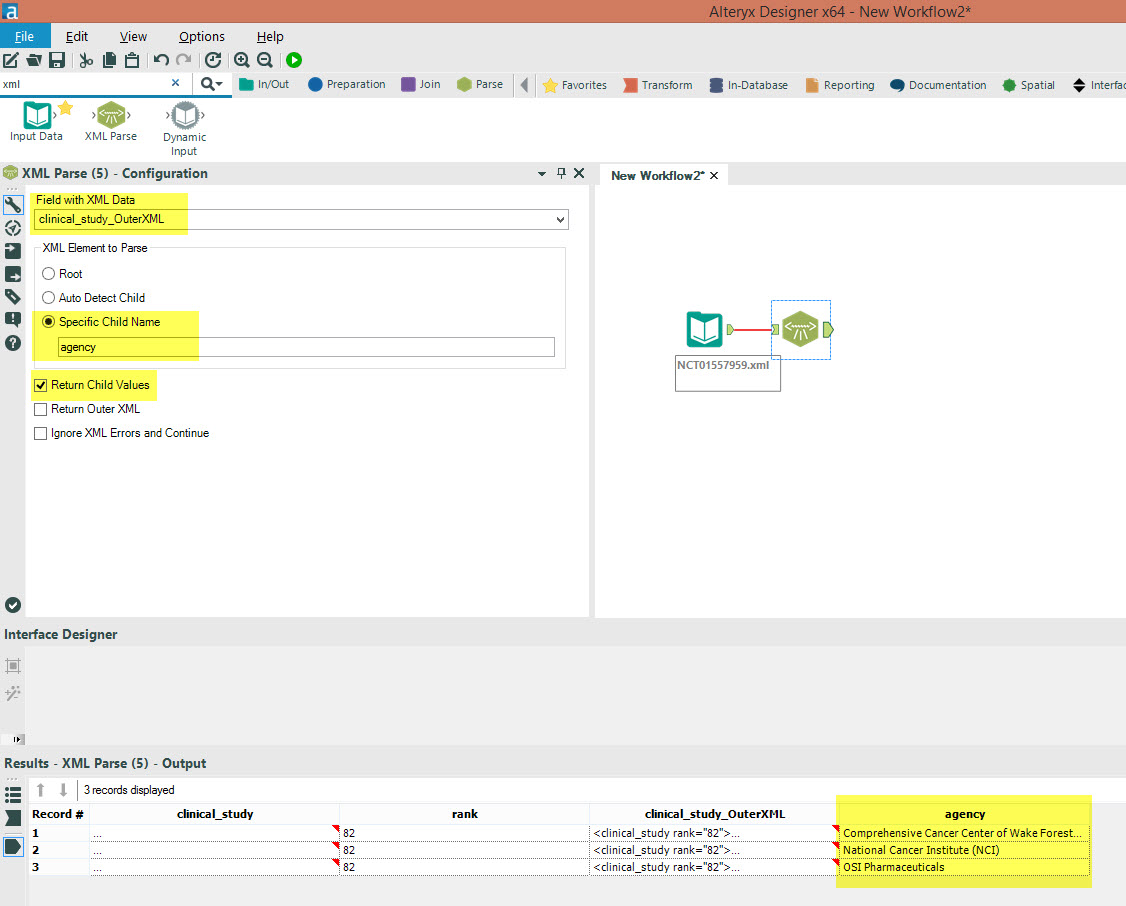 I've got the results window above with the <agency> data parsed!XML parsing requires a bit of evaluating the dataset and identifying where your data is located. Because of its nested nature, you might have quite of a few XML parse tools in your workflow. But the same concepts can be taken into web scraping with Alteryx so learning XML and its tagging system has transferable value!I hope this has been a clear introduction to working with XML files. Let me know if you have any questions in the comments section below.
I've got the results window above with the <agency> data parsed!XML parsing requires a bit of evaluating the dataset and identifying where your data is located. Because of its nested nature, you might have quite of a few XML parse tools in your workflow. But the same concepts can be taken into web scraping with Alteryx so learning XML and its tagging system has transferable value!I hope this has been a clear introduction to working with XML files. Let me know if you have any questions in the comments section below.
Example 1: Parsing from 1 XML fileLet's go through one recent example I was working on for a client - parsing clinical trial data from XML files. Let's say I wanted to 2 pieces of information - the name of the trial and when did it start. I like to take a look at the XML file to see where is the information located so I can figure out the best way to parse it.I've opened the file in notepad++ and highlighted the tags which show which pieces of data I am looking for. Note that the root element in this file is 'clinical study', and it just so happens that <brief_title> and <start _date> are child values.What happens when I select this file in Alteryx's input tool?Alteryx's default settings is to pick up only 1 set of the file's child values, so there's a lot of information not yet coming through.Result in Alteryx picks up the <condition> tag/element in the XML file.I can bring the information we are trying to parse into Alteryx by selecting 'Return Root Element' and 'Return Child Values' as the information we are looking for is only 1 layer beneath the Root Element.Simply add a select tool for the fields we wanted to parse and voila!But what if I want to parse data that is nested deeper within the XML file?Like if you wanted to find who sponsored the clinical trial?The data is nested within the <agency> tags, so its not a child value of the root element. This is where can use the Outer XML configuration to bring in all XML tags within the root element. From there, we can parse out the <agency> tags with the ..XML Parse Tool!Simply select 'Return Root Element' and 'Return Outer XML' in the input tool so Alteryx can identify both the root element and its respective nested tags.Then add the XML Parse tool and configure the tool to look for the <agency> tag within the new field 'clinical_study_OuterXML'.I've got the results window above with the <agency> data parsed!XML parsing requires a bit of evaluating the dataset and identifying where your data is located. Because of its nested nature, you might have quite of a few XML parse tools in your workflow. But the same concepts can be taken into web scraping with Alteryx so learning XML and its tagging system has transferable value!I hope this has been a clear introduction to working with XML files. Let me know if you have any questions in the comments section below.