

Internally we have started working with and hosting some aspects of our IT infrastructure in 'the cloud', via Amazon Web Services (AWS).
We are also a company that LOVES automation, and personally, I love Alteryx (as do most of our team), so I wanted to understand how we can use Alteryx to work with AWS.
One such way would be by making programmatic requests to AWS against it's services using the REST API, this would allow us to perform almost any task that you may want to do within AWS, such as launch an EC2 instace, or list the items within an S3 bucket.
HOWEVER, I quickly noticed that this process would be quite painful. The authentication process is quite complex, to say the least, and though it will be interesting to tackle at some point, it's not something high on my priority list, especially when there is another service that we can work with, the AWS Command Line Interface, or CLI client.
What is the AWS CLI?
Well, fortunately for me, AWS have created a great reference guide for their CLI client, including a page titled 'What is the AWS Command Line Interface', however, in short it is a platform that allows you to programmatically perform tasks against AWS from the command prompt on your local machine, using simple text commands, as outlined in the documentation.
Before you start, you must of course start by downloading and installing the CLI client, which can be done by using this guide.
Okay, I've installed it, how do I use it?
Lets open command prompt and start by configuring a profile in our account, a profile is a store for our access credentials which then allow us to reference the profile, rather than our credentials with each request.
You can also create many profiles, which is useful if you have different accounts with varyling levels of access in AWS.
In this case, I'm going to create an account titled 'S3_access' giving the security credentials of an account in AWS that has full access to S3, but no further capabilities.
To configure this account, I will first run the command
aws configure --profile s3_accessBy running this command, I will then be prompted to specify the accounts 'AWS Access Key ID', the 'AWS Secret Access Key', the 'Default Region Name' and the 'Default Output Format', I will set the latter to text but of course you don't have too (though this is probably the easiest format to then read into Alteryx)!
In my case I also left the region empty, as this is a variable that I would prefer to decide upon making the request.
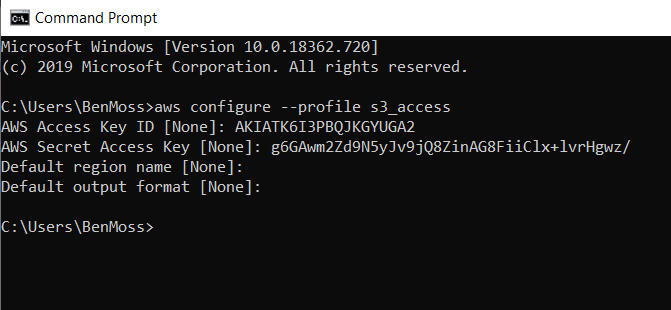
* As an FYI, these access credentials have been revoked, so don't even try *
Whenever you configure a profile, the information is stored in two files, located here...
%USERPROFILE%\\.aws
The config file stores information about the profile name and the default region and output types, whilst the credentials file actually stores the key information.
[default]region = eu-west-1output = json[profile s3_access]output = text[default]aws_access_key_id = ####aws_secret_access_key = ####[s3_access]aws_access_key_id = AKIATK6I3PBQJKGYUGA2aws_secret_access_key = g6GAwm2Zd9N5yJv9jQ8ZinAG8FiiClx+lvrHgwz/You'll see I actually have a default profile set-up, this is the account that will be used if I do not specify the --profile parameter when executing a command.
Now that your profile is set-up, I can just use a simple command against the s3api endpoint to return a list of s3 buckets on the account.
Note, having looked through the reference documentation for the list-buckets endpoint it seems that this does not respect the region parameter (as referenced in the code snippets and images below), so if I include this parameter or not, I will get a list of all S3 buckets regardless of their region.
aws s3api list-buckets --profile s3_access --region eu-west-2If the credentials set for the profile in use do not have access to this resource, then you can expect an error at this point (some bucket names are hidden in the below example for privacy reasons).

In this case, I get a list of the different buckets in our eu-west-2 region with which the profile has the ability to see; in json format, as specified as my default output type.
In addition, especially useful as we move through to performing this process in Alteryx, we can actually write the tab seperated list results to a file, by suffixing our statement with ' > outputfilelocation/outputfilename.outputfiletype'
so, something like the below command, will write my tab seperated list of s3 buckets to a .txt file titled 's3buckets'.
aws s3api list-buckets --profile s3_access --region eu-west-2 > 'C:\\Users\\BenMoss\\Desktop\\Work\\AWS\\Outputs\\s3buckets.txt'But why would I do this in Alteryx?
First of all, lets start with why we would even bother trying to get Alteryx to communicate with the AWS CLI, to me their are a few advantages...
Reason: the ability to make your script more dynamic
Example: I want to get CloudWatch logs for the last 12 hours, I can do this by setting --start and --end parameters, but the parameters require the time to be in the number of milliseconds since January 1st 1970. This is a calculation I am quite competent in performing in Alteryx but not so within command prompt.
Reason: the ability to perform complex data transformation in the same single process as the initial transaction to get the data in the first place
Example: I have downloaded the data into a text file, but there are a series of business rules, and filters that I want to apply before loading the data into our data warehouse. This is something that is second nature to me, at least in Alteryx, I've never used command prompt for data prep before, nor do I think it will be easy!
Reason: making your work easy to understand
Example: If I'm working in a business that is looking to deploy code free solutions for the business for the purpose of making complex processes more visible and easier to understand, it would go against that matra if we were to deploy a complex command line script that people may not easily be able to understand. Though we must still execute the actual fetching of the data using the CLI we can perform all of the pre and post transformation tools in Alteryx.
I guess both points here boil down to the users experience working with command prompt. If the user is happy to perform complex data transformation statements on-top of the initial script to retrieve the data, then go ahead and use the CLI, however, if you are more comfortable using Alteryx and this is the tool of choice for your business, then it makes sense to use leverage Alteryx's code friendly environment to maximise your output.
How do I do this in Alteryx?
In order to communicate with the AWS CLI from within Alteryx we will need to make use of the Run Command tool, which exists in the developer tool palette.
However, we must first create a datastream, with a single cell of data, containing the script which we want to trigger. My way of approaching this task would be to create a text input which contains a field called 'script' which a value 'script here'.
We can then overwrite the 'script here' value with a script curated via a formula tool, which would allow us to add dynamic variables if required.
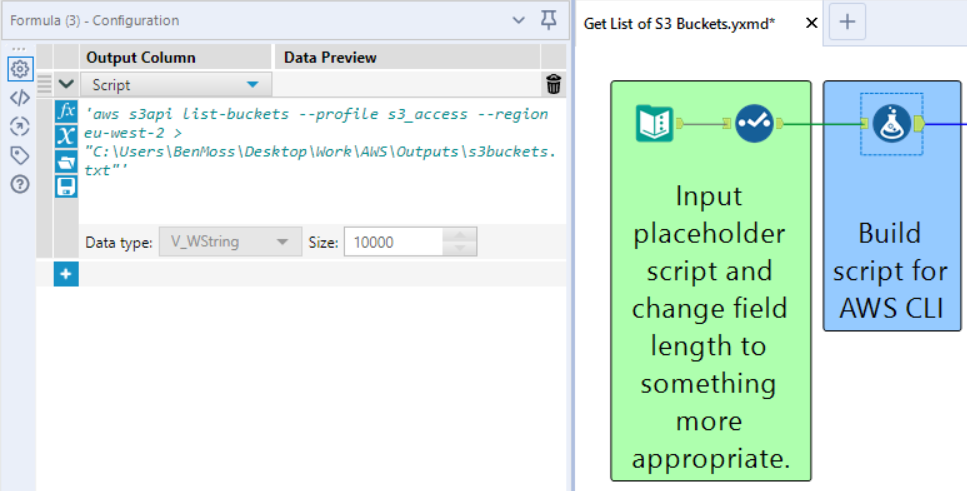
Once we've built our script we can then get going with the Run Command tool, if you've never used it before the configuration window can look a bit daunting, but that's why I've shared a screenshot of mine, and I'll outline below why I have configured each part as I have.
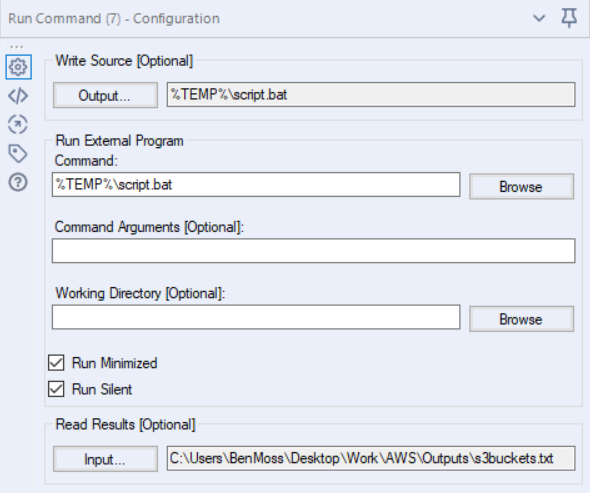
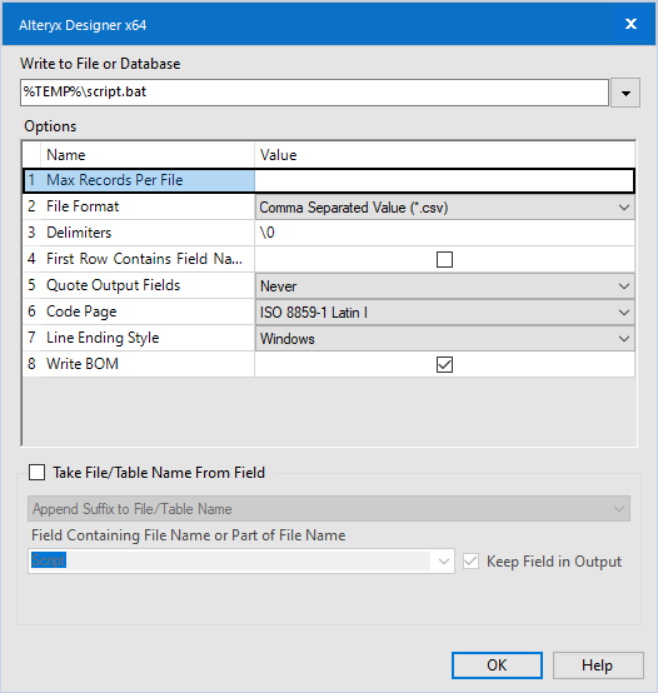
The 'Write Source' option allows us to write the data stream coming into the Run Command tool to a file. In this case, I am writing our script to a '.bat' file which we can later execute. Bat files are not a native output type in Alteryx, so we must choose the '.csv' file format from the list and then change the extension manually in the output path.
There are a few key configurations to take note of here, specifically, setting the delimiter to \\0 (no delimiter), unchecking the 'First Row Contains Field Names' option, and finally changing the 'Qoute Output Fields' option to 'Never'.
The next aspect to configure is the 'Command', this is the file that we want to execute, in this case, it's the .bat script that we had written directly above.
The final step is to specify the Read Results. In this case we want to read the file which is created by our script, the tab delimtied text file which contains our list of s3 buckets.
So this tool has 3 process stages if you like, 1. write a file, 2. execute a command, 3. read a file.
The datasource set in the 'Read Results' option will then be streated via the output anchor of our Run Command tool, where we can therefor perform a whole series of data transformations as required, before outputting our data.

I hope this was mildly useful; Alteryx themselves have blogged about this, though they present a slightly different solution it's pretty much identical.
Ben