

Before Christmas I ran a Sentiment Analysis 3 ways webinar (see the post here) and I promised to create a text version of the post for reference. That is what I'm doing here.
Before I get into the how to do sentiment analysis. I want to refresh our memories as to what sentiment analysis is and why you would want to implement it.
Sentiment Analysis is the process of trying to determine the attitude of a what you are analysing. Basically you are trying to decide, is what they said good or bad to me?
So what are some use cases for sentiment analysis? Well, in my opinion, it's all about trying to become proactive to whatever people are saying. If you know what your customers are saying, and you know what they are saying is changing you can do something about it either good or bad.
Five specific use cases are:
- Target individuals to improve their service
- Track customer sentiment over time
- Determine if particular customer segments feel more strongly about your company
- Track how a change in product or service affects how customers feel
- Determine your key promoters and detractors
Sentiment analysis via API.
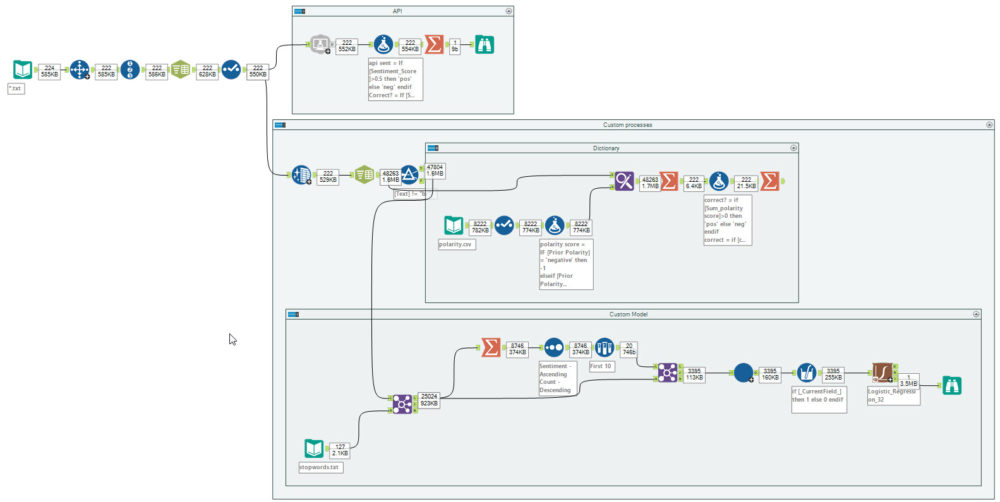
To do sentiment analysis via an API, the process is super simple. In the image above most of the process is creating a identifiers for each review and splitting creating the sentiment flag for comparison.
In the API box, is where the sentiment analysis takes place. The MS Cognitive services tool from the Alteryx Gallery by filling in 4 parameters, your MS API Key, the endpoint for that key, what field you want to analyse and finally, what sort of analysis you want (sentiment in this example). That is all, the API returns a value between 0 and 1 (0 negative, 1 positive).
Dictionary Sentiment Analysis
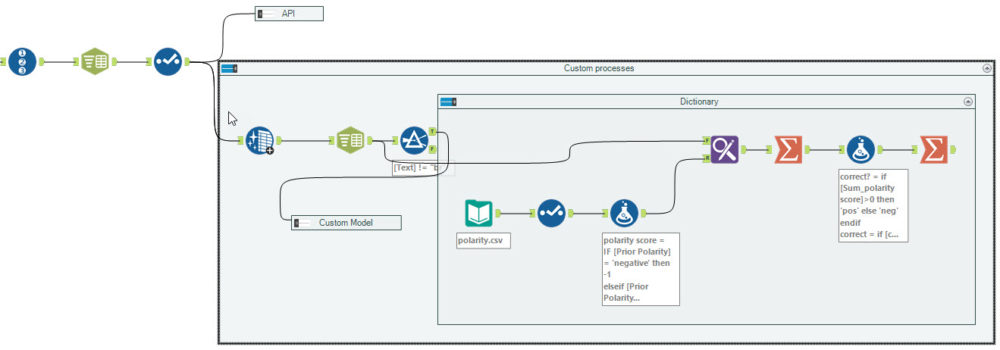
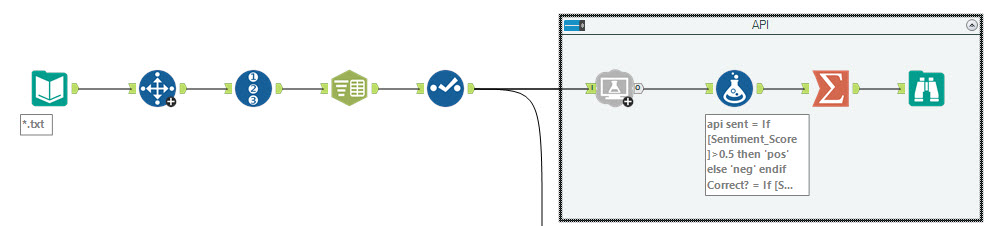
The Second process I looked at was a dictionary sentiment analysis. This process takes a dictionary of words that you have assigned a positive or negative value to (in my example +1 for positive, -1 for negative). The process for defining the dictionary can be taken from some existing lexicons (like the one from the University of Pittsburg that I used in the webinar) or you can create them manually from scratch for the words that are important for you and your application.
The next step is to prepare your reviews or text. This process requires each word to be its own record. I achieved this using the Text-to-Columns tool with the selecting the Text to Rows option with a space (\\s) as the delimiter.
Now you will have the two data feeds ready; your text list with each word as a record and the sentiment dictionary. It's time to assign sentiment to each word. I used the Find and Replace tool looking at the text field and applying the sentiment for each word.
The final step for dictionary sentiment analysis is to aggregate back to the original review level. Using a simple sum aggregation, the more positive the value the more positive the sentiment.
Full Custom Model
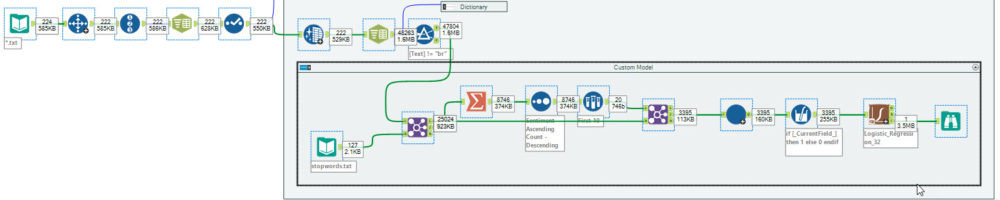
The final way I presented to complete sentiment analysis is to create a full customised classification model. We use the same individual words preparation from the dictionary process but instead of applying the dictionary we will build a classification model.
When we go to build the model the first thing we want to do is remove all the common english words that add no value to the final model, words like me, who and having. You can also remove words like your company name or a specific technology you use that don't add any further value (you can test by training the model with and without those words and compare the performance).
Optional training speed boost
During the webinar I had limited time so the model I built was compromised for the sake of speed. In this case I counted the appearance of each word for each sentiment, and just focused on just the most common 10 words for each sentiment.
Back to the model
Next, for the model training we need to transform into what is called a One-Hot-Encoded format. One hot encoding is where each individual variable (each word in our case) which will have a 1 if that word appears in that review and a 0 if it doesn't.
The final step is to apply the model. The model I decided to use was a Logistic Regression model. It is one of the simpler machine learning algorithms but is good for this example. I used all the top 10 words (from the optional speed boost section) with the target field of the pre-labelled sentiment.
What Next?

So the model that was created in the webinar wasn't that good (the accuracy was only 50% so it was just random guesses) but that is a function of the compromises that were made in the interest of training speed. But what can be done to improve the performance of the model?
- Use all the reviews available (I only used 200 of the 25000 reviews in the corpus).
- Use all the words in the model training (more features, more possible predictive power).
- Stem the words so words like run and running are treated the same.
- try different model types (like a Random Forest) or some other deep learning model.
Thanks for your time and I encourage you to watch the seminar from my previous post.