


Intro
I was introduced to relationships in PowerBI and wished Tableau had an equivalent. So, I was ecstatic when Tableau 2020.2 added relationships AND made them more flexible than they are in PowerBI!
However, with great flexibility comes great risks. One of the minefields shows up when we try to connect more than two datasets. In this blog, I will explain how to make sure you don’t lose any data when connecting more than two datasets.
How do relationships work?
We don’t need to go into detail on how relationships work. But if you’re interested, you can check out Henry’s short introduction or Tim’s deep dive.
According to Tableau:
'Relationships are a flexible way to combine data for multi-table analysis in Tableau.'
Put simply, we give Tableau instructions on how to join our datasets and it will join them in the background as and when appropriate.
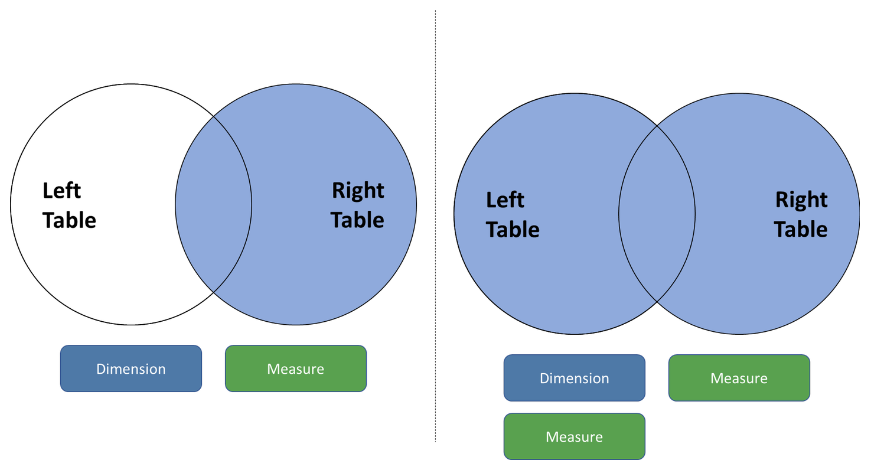
It’s also important to remember that dragging in measures from a dataset instructs Tableau to include all values from that dataset. For example, dragging a measure from the Right Table will create a left join (see figure 1). Dragging in measures from both tables would create a full outer join.
Direct and indirect connections
Much of the extra flexibility I mentioned comes from the fact that, by default, data can flow both ways and through other data sets. For example, in figure 2, we can create a chart which looks at which people made X number of returns without usin fields from the Orders table.

This practically creates two types of connections:
- Direct connections: where there is a defined, direct connection between two data sets (e.g. People and Orders)
- Indirect connections: where data flows through one or more other datasets to connect to the intended dataset (e.g. People and Returns)
We must be extra diligent when using indirectly connected datasets!
This is because we can lose or duplicate rows without realising. There is currently no indication of when this happens so you have to be aware of how you (and Tableau) are using the data.
Case of the disappearing data
The major problem with indirect connections is that the intermediate datasets must be, at least, as complete as the datasets being used. Revisiting figure 2, we will lose a datapoint if it exists in the People table and Returns table but is missing from the Order table.
This is because Tableau creates a join in the background with all datasets involved in the connection - including the intermediary datasets. However, the join(s) happen chronologically. First, People is joined with Orders using the given join condition (i.e. columns from People and Orders). Second, this new table (People-Orders) is joined to Returns using the key columns from Orders and Returns. This means that if a record is missing from Orders, then it cannot join with Returns because the join condition cannot be met.
You may be wondering “what’s the big deal? A join would have the same issue!”
Well, the problem isn’t the existence of this limitation but that it happens in the background! When joining data, we’re painfully aware of everything that can go wrong and most data transformation software have tools to help identify them. But it’s not always clear (even if you’re looking out for it) what kinds of joins are being created by the numerous charts, dashboards and actions in a workbook.
Solutions
I can tell you to “just be careful” but there are other steps you can take to minimise risk:
Joins
I sound old-school but joins are as reliable as data connections get. Consider joining some of the tables (especially if they’re small). The cost may be flexibility and performance but that’s outweighed by trust in the data.
Limit the scope of the relationships
Do you really need all these datasets connected (directly or indirectly)?
Reducing the number of intertwined tables reduces the risk they’ll get tangled without you noticing. An alternative is to create a new datasource. This would let you use all your datasets in the workbook without risking this issue.
Make sure there are no missing records
This is the ideal solution. But it can be hard to confirm and maintain.
Relationships can be created freely if your datasets (especially intermediaries) have the same list of values.
You can even populate only the key columns (leaving other columns null) for the sole purpose of ensuring no rows are lost in indirect relationships.