

I was using my Mahalanobis Distance calculation recently on some of my Spotify listening data, and I ran into difficulty. When I calculated the MD value of one song compared to the benchmark group, it gave me a value of 3.12. Nice. But, when I calculated the MD values of several songs at once compared to the same benchmark group, I got a value of 0.67 for that same song that was 3.12 when calculated individually. The same thing happened for lots of other songs; I got one value when calculating it individually, and another when calculating a whole bunch of them together.This was weird, and after several hours of diagnosing what was going on, I finally found it. There's an inconsistency with the Crosstab tool that I'd never noticed before, and this had a critical knock-on effect.I'll walk through it step by step with some random data. Here's the content in a text input tool; note the variety of capitals, lower case, and numbers: For the MD calculation, what I need is two tables; one where there's a column for each Thing Name, like this:
For the MD calculation, what I need is two tables; one where there's a column for each Thing Name, like this: And one where there's a row for each Thing Name, like this:
And one where there's a row for each Thing Name, like this: It should be simple to generate this, but it isn't because the Crosstab tool orders the Thing Name alphabetically.First, let's see what happens when generating the table with Thing Name as columns. Set the Crosstab tool up like this (for the aggregation, you can choose First, Average, Sum, it doesn't make a difference with this dataset):
It should be simple to generate this, but it isn't because the Crosstab tool orders the Thing Name alphabetically.First, let's see what happens when generating the table with Thing Name as columns. Set the Crosstab tool up like this (for the aggregation, you can choose First, Average, Sum, it doesn't make a difference with this dataset):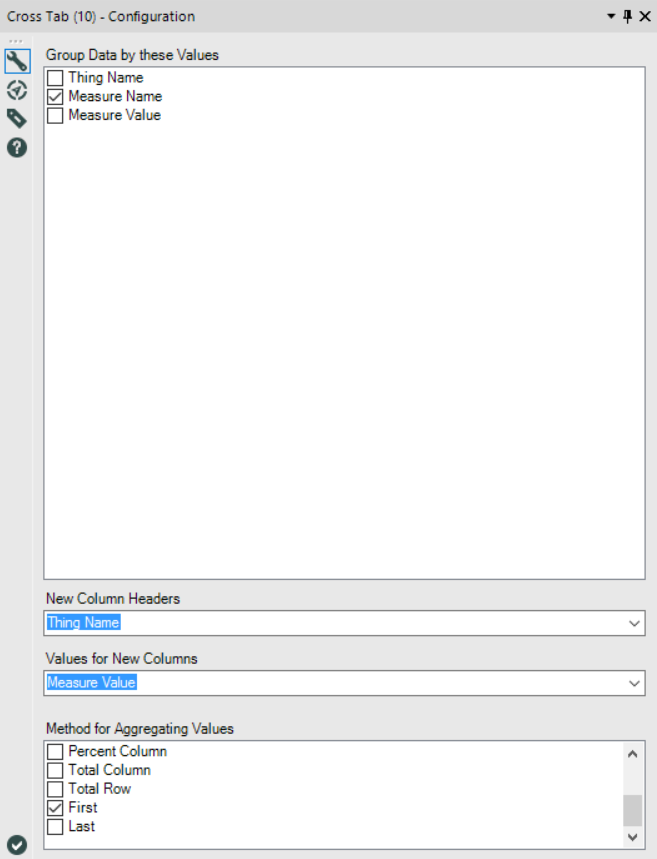 Run the workflow, and this is the output. Note how the output has reordered the Thing Name alphabetically:
Run the workflow, and this is the output. Note how the output has reordered the Thing Name alphabetically: It's put the Thing Names beginning with numbers first, put those in ascending order, then taken all the Thing Names beginning with letters, and put those in alphabetical order a through z.Right. Let's now look at what happens when generating a table with one row per Thing Name. Set up the Crosstab tool like this (again, aggregation method doesn't matter):
It's put the Thing Names beginning with numbers first, put those in ascending order, then taken all the Thing Names beginning with letters, and put those in alphabetical order a through z.Right. Let's now look at what happens when generating a table with one row per Thing Name. Set up the Crosstab tool like this (again, aggregation method doesn't matter): And here's the output:
And here's the output: This time, it's put the Thing Name in the rows in alphabetical order slightly differently. First come the Thing Names beginning with numbers in ascending numerical order as before... but then it's treating Thing Names beginning with CAPITAL LETTERS and Thing Names beginning lower case letters separately. It runs through the capital-first Thing Names A through Z, and then and only then does it run through the lower case-first Thing Names a-z.Considering that the MD calculation involves matrix multiplication where it's assumed that the order of items in the rows and columns is identical, this creates a massive problem down the line!There are two solutions. One is to CAPITALISE EVERYTHING before even starting, which will probably work in most cases... but if your Thing Names are identical except for case (e.g. if XXX, xXx, and xxX are different variables), it will collapse them together a bit like it does for punctuation. This is not ideal.The other solution is to use record IDs and manual reordering to ensure that the rows and columns stay in the same order, like this (which is how I generated the first two tables in this blog):
This time, it's put the Thing Name in the rows in alphabetical order slightly differently. First come the Thing Names beginning with numbers in ascending numerical order as before... but then it's treating Thing Names beginning with CAPITAL LETTERS and Thing Names beginning lower case letters separately. It runs through the capital-first Thing Names A through Z, and then and only then does it run through the lower case-first Thing Names a-z.Considering that the MD calculation involves matrix multiplication where it's assumed that the order of items in the rows and columns is identical, this creates a massive problem down the line!There are two solutions. One is to CAPITALISE EVERYTHING before even starting, which will probably work in most cases... but if your Thing Names are identical except for case (e.g. if XXX, xXx, and xxX are different variables), it will collapse them together a bit like it does for punctuation. This is not ideal.The other solution is to use record IDs and manual reordering to ensure that the rows and columns stay in the same order, like this (which is how I generated the first two tables in this blog): This was an incredibly simple thing that was messing up my calculations, but it took me hours to find. If you're running into issues - and even if you don't think you are - check the order of things in your tables!
This was an incredibly simple thing that was messing up my calculations, but it took me hours to find. If you're running into issues - and even if you don't think you are - check the order of things in your tables!
Originally posted on Gwilym Lockwood's personal blog