


We've all felt it before. The moment when somebody tells you they've got an amazing dataset. It ticks all the data-viz enthusiast's boxes, it's interesting, the potential stories are coming to you with every thought and it's BIG data! So you follow their link only to find you're downloading a file ending .csv
CSV!? Seriously! This is how we transfer data in 2019...as TEXT! And don't think just cause you've zipped & compressed it you're fooling anyone. The distributor may as well as chiselled it into stone.
Yes Tableau can connect to it & extract it, but that means you're destined to stare at...
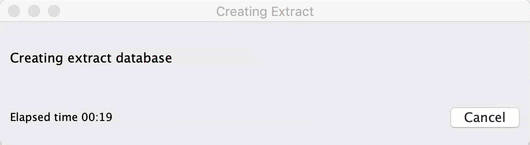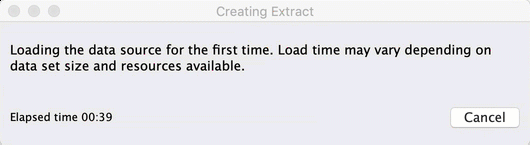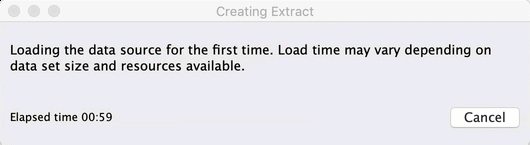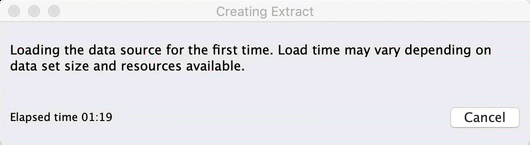
And who wants that?! Tableau's about being fast, and staying in the flow...and connecting to your amazing, interesting, fantastic dataset NOW!
Hyper. You haven't seen anything yet
What if I told you that it was possible to convert that CSV into a Tableau Hyper file in less time than it takes the GIF above to loop? How about half the time? Well put away your credit cards, no fancy cloud database needed here. We can do it using the brand new Hyper API.
Previously known as the Extract API, the Hyper API allows us to generate Hyper files via Python, .NET, C++ or Java (for those of you non-coders out there, don't worry! A nicely packaged solution is available further to download below).
So what's changed? Well on the face of it not much. The Extract API worked with Python, C, C++ and Java, just like the Hyper API except for C & .NET. You'd build a table and then populate it row by row, same with the Hyper API.
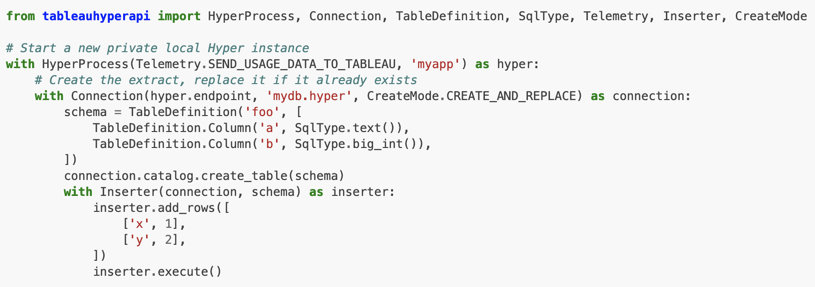
However look a little more closely at the documentation and you'll find this:

Yes, that's right. You can execute SQL commands directly in the API.
So what? COPY baby!
Hyper is build from scratch however it follows a lot of Postgres syntacs and semantics. That means you can make use of some Posgres style commands such as COPY FROM CSV. And it's that which allows the API to work its magic and bulk load a CSV file.
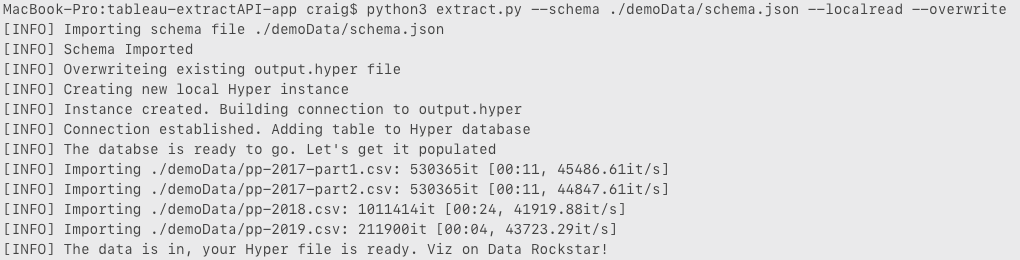
Now we're all data people, let me talk to you in a way we can all understand...statistics. I loaded 4 CSV files totalling 400MB (not big yet I know) into a single table into a Hyper extract using the old Extract API, the new Hyper API with the row inserter and then the new Hyper API using the SQL COPY FROM command. The machine taking on this task was a MacBook Pro i7 with 16GB RAM.
The old Extract API finished building the Hyper file in 183 seconds or 2.18MB/s (when you're in the low single digits the extra .18 matters).
The new Hyper API inserting records one row at a time finished the same task in 50 seconds or 8MB/s.
The new Hyper API using a SQL COPY FROM CSV command however...

Yes I know I iterated on the status output but you're not reading it incorrectly. 4 seconds! That's one second per file or 100MB/s.
But I hear you. 400MB Craig, that's not big data! OK so how about the complete recorded history of house sales in the UK. That's a 4.3GB CSV. Think we can improve on 100MB/s?

Oh yes we can! 34 seconds for 4.3GB or 126MB/s.
Packaging it up for you
So this is all great but who wants to learn Python or C++ to make use of a super fast data engine? Don't worry, we've got you covered. Head over to our Github page where you'll find a preview release of a command line tool for either Mac or Windows (if you'd like Linux then please request it via the issues page).
Currently it is just command line however there are plans to give it a nice GUI front end in a future release. Here's the --help output:
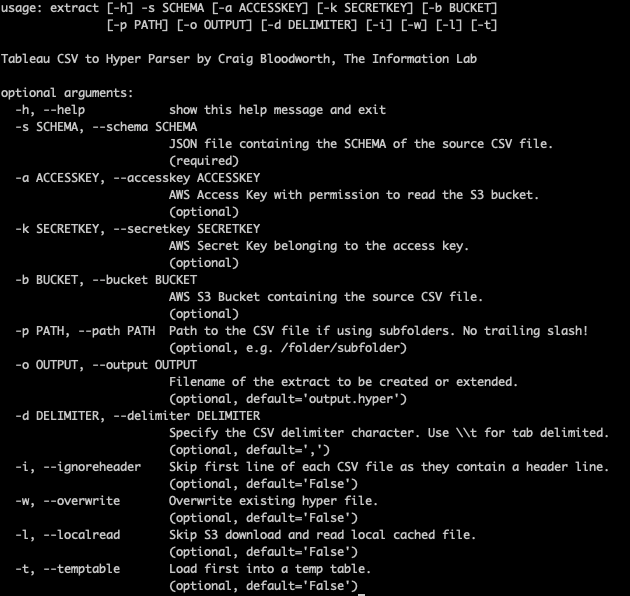
In terms of your source data you have two options either local storage or AWS S3 (Google Cloud Platform coming soon). If your files are local then you're going to add the -l switch (or --localread), if it's in S3 you'll need your credentials in the form of Access and Secret keys with permission to read from the S3 bucket. If you're at all unsure about AWS permissions you're looking for:
'Effect': 'Allow','Action': ['s3:GetObject','s3:ListBucket']which will reference the bucket in question and any (or a specific) object within that bucket.
Once you have your creds you'll make us of them through the switches:
--accesskey [Insert AWS Access Key]--secretkey [Insert AWS Secret Key]--bucket [Insert The Name of the Bucket]--path [Optional, provide a path to the CSV file]Other than the location of the source (local or S3) the only other requirement is a schema. In this case we're going to write a .json file which will tell the app how to construct the Hyper file. For those of you who are familiar with JSON here's a schema definition for what's required. If not then here's a super basic, example schema json.
{'name': 'my_table','files': ['sourcedata.csv'],'columns': [{'name' : 'Column A','type' : 'TEXT'},{'name' : 'Column B','type' : 'INTEGER'},{'name' : 'Column C','type' : 'VARCHAR','length' : 200}]}In the example above you've got the first attribute 'name' which describes the name of the table in the Hyper file (yes a Hyper file can have multiple tables). Next you have a list or array of your source CSV files listed under the 'files' attribute. If you want more than one file just comma separate the list, for example [ 'file1.csv', 'file2.csv', 'file3.csv' ]. Each file will be appended to the table in the Hyper file.
Finally we have the list of columns. Each column object enclosed by curly brackets { } has a name which is how you want the column to appear in Tableau and the type. The type can be any of the following:
'BIG_INT','BOOLEAN','BYTES','CHAR','DATE','DOUBLE','GEOGRAPHY','INT','INTERVAL','JSON','NUMERIC','OID','SMALL_INT','TEXT','TIME','TIMESTAMP','TIMESTAMP_TZ','VARCHAR'However for this early pre-release of the HyperAPI I'd stick with either BOOLEAN, DOUBLE, INT or TEXT. If you do want to use CHAR or VARCHAR then you'll need to also declare a 'length' attribute for the column and for NUMERIC you'll need both a 'precision' and a 'scale' attribute. All three of these attributes are declared as integers.
It's worth noting that each of your source CSV files must have the same structure in terms of number of columns and the order of those columns which must match the number and order of columns declared in the schema json.
Once you've written your schema json file you simply declare it as another switch:
--schema myschema.jsonAnd that's it. So for the most basic example, a local file using a standard CSV file with no headers the command would be:
WINDOWSextract.exe --schema myschema.json -lMAC./extract --schema myschema.json -lAs a side note, if you're using a Mac and you've just downloaded the extract binary you'll need to give that binary permission to execute. To do that simply run the following command in the same folder as the binary:
chmod +x ./extractSo what's next?
Well first of all I hope this comes in useful. If so please feel free to reach out via Twitter and let me know what you've managed to push through it. If you have any issues then do raise them via the project's Github issues.
Next I'd like to add a nice front end to this app allowing you simply drag and drop your local files or select you files from an S3 bucket. Clearly having to hard code your own schema json isn't ideal, I'd love to add an interface to make creating it much easier and ideally auto generating it. As I mentioned earlier I'd also like to expand to make use of Google Cloud Platform's storage.
If you'd like it to do anything else then please do let me know via Github.
Enjoy!
[Correction] In the original version of this post I said 'If you’re not aware Hyper is built on the back of PostgreSQL.' This was my misunderstanding where in fact Hyper was built from scratch but makes use of Postgres syntacs and semantics. There was also a missing statistic showing the speed of the original Extract API which has now been added.