

I recently wrote a blog which looked at how we can 'reject' inputs with the use of a data dictionary and the test tool.
The data dictionary gave detail on the name of every field in a dataset, the data type of those fields and also the size.
We also created a placeholder field which allowed users to add a definition to the file should they wish to allow others to understand the source in more detail (a great idea for handover!).
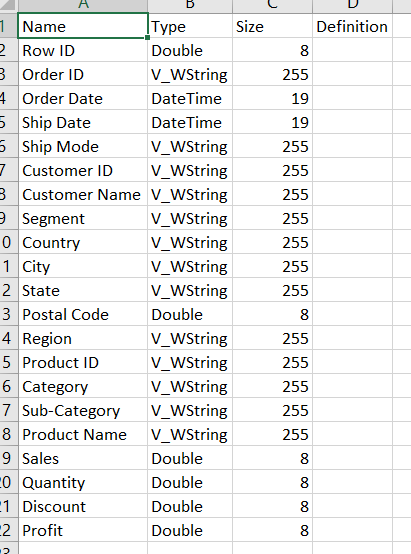
When demoing this solution to a client, they mentioned that including example values for string fields could be valuable, whilst showing the range for numeric and date datatypes would also be important in order to give those looking at the dictionary an idea of the values that may exist in the column.
It's certainly possible, and relatively straight forward to do with the help of the data investigation toolkit.
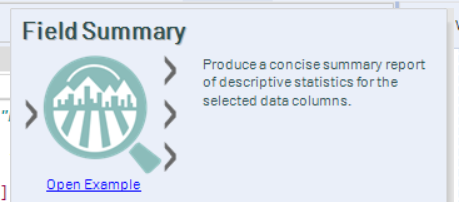

The Field Summary tool allows us to get a high level overview of the contents of fields, including things like the number of unique values; the max and min values, and the standard deviation. It also gives a useful indicator on the number of missing values (either empty or NULL).
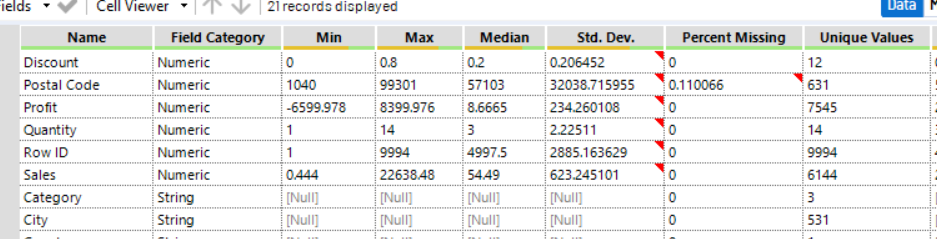
Clearly this is more useful for numeric values rather that string values; this is where the frequency table tool comes in, which gives a list of all values in a field and how common they are.
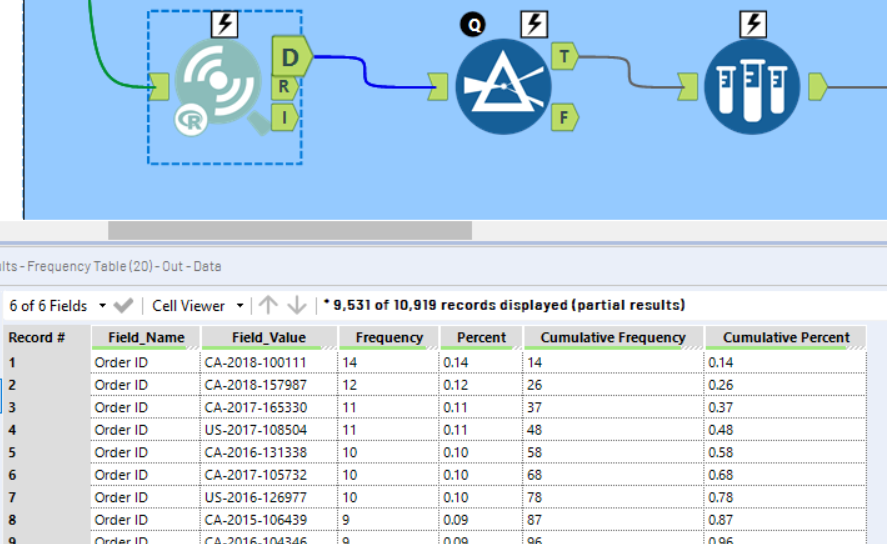
We can easily take a small sample of the most common values and include these in our data dictionary (using the sample tool!).
We can then loop this into our workflow in order to include them in our data dictionary output.
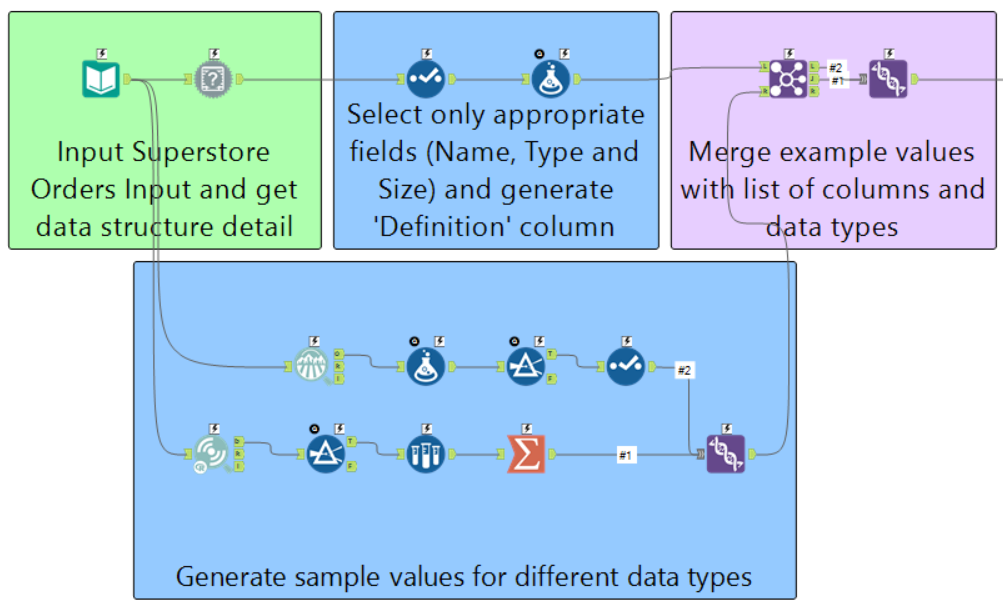
An example workflow of this process implemented can be found here; unfortunately these predictive tools don't allow for the 'unknown' fields capability, which makes building an application to perform this process a bit more difficult, which is not something I want to cover in the post, but I have done it, and an app which generates the data dictionary plus example values can be found here.
Ben