

Moving on from ETL
Decades ago the thinking was everything data in a business area would be provided within a single tool. You wanted an application that could ingest your daily business activities (perhaps even manually if necessary), manage and transform the data however it decides, give you workflows based on both common and custom business logic and provide a suitable reporting output. Any access to underlying data was restricted and if accessible, only granted to specialist users.
As the need for data grew, first driven by the popularisation of data warehousing and data cubes and then by innovative data visualisation tools such as Tableau, tools emerged which sold themselves as "extract, transform & load (ETL) solutions". These would operate on multiple source systems and push data into a "single source of truth" on-premise database.
As the need for data grew the storage sizes and ETL processing requirements started to overwhelm these classic on-premise solutions. New in-memory technologies and cloud-hosted offerings started to become popular on the back of their more advanced storage and processing capabilities, switching the pipeline from ETL to ELT. Effectively get the data into the database as quickly and raw as possible and use the almost unlimited database power to transform it however you need.
The common theme so far has been a small handful of tools to rule everything. That was understandable back when host systems were limited but we now live in a world where virtualisation is mainstream across consumer systems, machines are available in the cloud at the click of a button and most tools have a cost-effective SaaS cloud offering. In other words we are no longer restricted to one tool or even one provider’s suite of tools to cover every requirement.
What about "The Modern Data Stack"?
As is often the case in technology the name doesn't match what you might think of at first. The modern data stack is not a collection of tightly coupled tools or even a short list of the best tools to use today. It is instead a framework in which you can utilise the application best suited for that particular use case.
The use of the term “Modern Data Stack” was popularised a few years ago as a marketing term to inject hype into the analytics market. The launch of truely cloud-native tools and databases cemented the need for analytics to move away from on-premise tools and cut up their stack into its various components. Some components would remain on-premise with others moving to the cloud. In some organisations however the number of components and the variety of tools selected exploded, adding complexity to an already fairly complex space.
It doesn’t have to be like that. The modern data stack as a framework can be useful as a way to evaluate whether you are too locked in to one specific tool, whether you could be taking better advantage of more specialist applications, and if there is an area you are missing or haven’t fully explored.
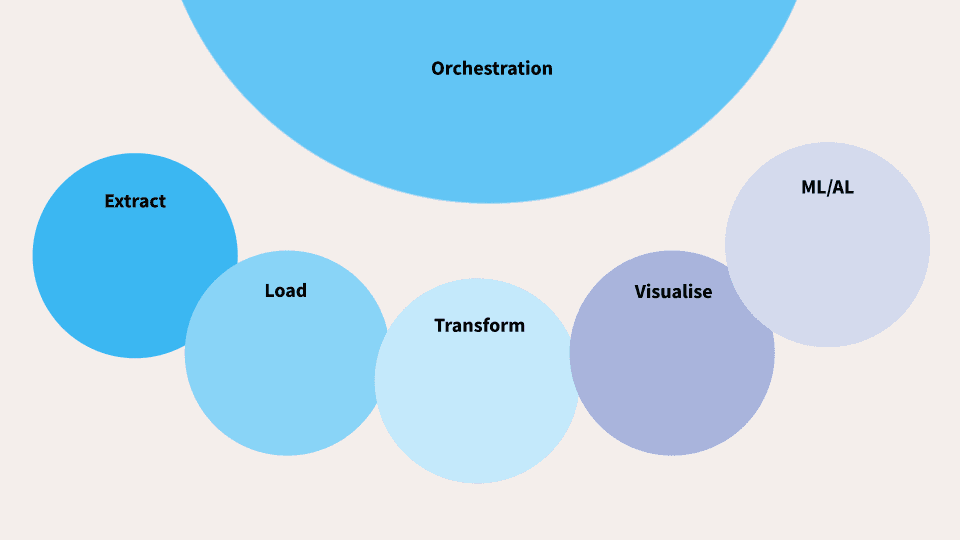
For our purposes we are going to look at this fairly simple but effective analytic stack and run through each component in turn.
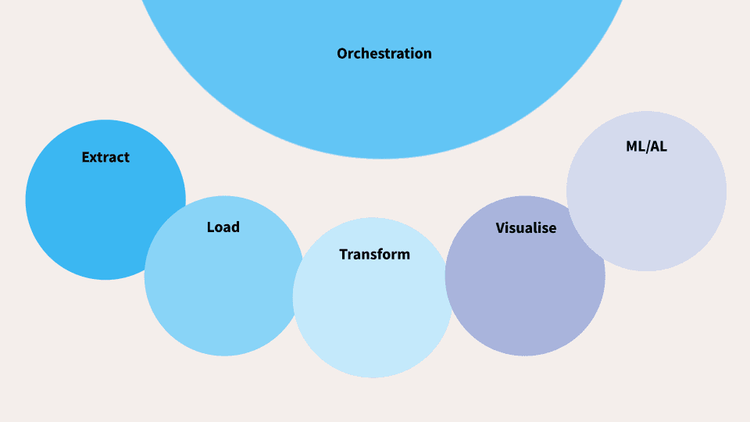
Extract
Yes extract, transform and load are still there but they are individual components rather than one wholesale solution. After all everything starts with data, that data is probably in an application fulfilling a business need and we need a way to get it out.
Selecting a tool to do this will clearly be determined by its ability to connect to a business application either via an underlying database or an API. Consideration should also be given to the volume of the extract, is the tool expecting to respond to single row insert and update transactions or will it be a bulk extract of many thousands or millions of records at a time, and the frequency of refresh be it daily, hourly or real-time.
Load
Theoretically transform could come before load as it once did however ELT has been the more common order since the creation of the modern data stack and it prevails in our version.
At this point data load can be considered "bulk data storage." You are looking for somewhere fast and convenient to store the extracted data in a way which can be easily referenced by your transform tool. If you have a data lake in your organisation then that is what you'll be targeting. It should have almost unlimited storage capacity, at least so much that there’s no need to consider it, and the potential to process large amounts at a time.
Transform
Here's where the fun starts. While the tool you choose needs to work with the format your data landed in, be that tabular or unstructured nested JSON for example, the most important consideration is the current and potential skillset of your team.
In the transform stage you are taking this raw data, modifying it to match the output you need for analysis and potentially enhancing it by merging with other data sources. This is where you are most exposed to change as source applications are upgraded and analysis needs further up the chain develop. Think long term, it's really tempting to handle it all in code and keep costs low but an investment in drag and drop tools allow skills to be more easily transferred from one data worker to the other.
Visualise
Of all the stages it is the final visualisation that often gets the most attention. Done well data can be explored, insights shared, debated and decisions made. Done poorly and all of your hard work ends in the question "how can I export the data?" Along with ML and AI these are the points at which the most feedback and change requests will come from for the previous stages.
When executing the visualisation stage it is important to know the audience just as well as the data. Will they want simple and dependable insights delivered regularly to their inbox or via the company intranet or will they want a window onto all of the data stored in the organisation to find hidden insights? The key goal here is to enable the entire organisation at any level to make informed, data-driven decisions.
ML and AI
The new kid on the block...or at least the one getting the most attention at the moment is artificial intelligence. The more precise term of “artificial narrow intelligence” is better suited to organisation data. Despite all the hype surrounding AI, most applications in this space are a single step evolution of machine learning (ML) models achieved by combining them with large language models (LLMs) to create a more human-readable output.
Features we are going to be looking for at this stage are things that humans aren't that great at such as outlier and pattern detection and quick summary insights which can help introduce a user to a particular dataset. What is key however is unlike visualisation where an insight can be derived from just a few data points, AI performs best when it has a large dataset to work on and the data is formatted in a way which aligns with the likely questions to be asked. Implementing AI can therefore dramatically increase the workload on the ELT stages.
Orchestration
Finally in our analytic stack is orchestration, the watch-tower on all our other stages. One of the downsides of decoupling ourselves from one monolithic application which tries to handle everything is making sure each individual tool works as expected and in a logical order. After all there is no point in a management team debating what a critical dashboard is showing them if the latest data doesn't land for another couple of hours.
The orchestration tool is the heads-up display the data engineer or administrator will rely on to make sure all is working as designed. It is also the tool that will bring efficiencies to the entire process. While it is possible to set your visualisation tool to extract from the data lake every 30 minutes to ensure you have the latest data despite not knowing when it will land, this is costly in terms of compute and potentially billing. Orchestration means your data transforms only after it has been loaded, and that visualisations or AI models are only refreshed using the most up to date data. It can also handle your business workflows and logic by responding to events and requests as they occur.
So the modern data stack was just to sell me more tools?
Not necessarily. Yes breaking up monolith applications means more than one tool is now needed, however the beauty of the analytic stack we have been looking at is it is totally up to you. You might choose one tool to cover two or three of the components. Your selection might be consistent across your organisation/department or it might vary by use case. With each combination of tools there will of course be strengths and weaknesses, be they price, complexity or availability of support services. By the end however you should have a robust and efficient solution which addresses the entire use case with as few compromises as possible.
In the next blog post we will look at what you should look for in the selection of tools and highlight some of our favourites at The Information Lab.