

23 May 2014
Our Alteryx Tools in Focus series continues with a look at the 'Calgary' tools. An often overlooked set of tools that can make a big difference to the way you use and consume large datasets as an Alteryx user.So what is Calgary? Simply put Calgary is an indexed database allowing quick retrieval of records from a large dataset. How big is large? Calgary databases have a limit of 2 billion records, but mostly I see them being used for datasets of between 100 million and 1 billion. How quick is quick? It depends on what's being retrieved but in a typical use case I'd look at retrieving records in less than ten seconds from these large datasets. This is what we can expect in our log: Impressed yet? I was considering the example above ran on my laptop - not an expensive server.Why might you use a Calgary database to store data?As a database manager or developer you may not have much need for another database tool, but as a line of business user then Calgary can be a very important way of speeding up analytical processes where these kind of large datasets are bei ng used and IT resources are either expensive or difficult to use. Who wants to wait weeks for specialist IT resource to build a database and design an index? You don't need to if you are using Alteryx because the tools are right in front of you and you can build a database quickly and easily without any development skills being needed. Clearly there is still a need for best practice around the management and use of Calgary files, but, in the right situation, I've used Calgary to devastating effect within Alteryx.Calgary comes with Alteryx out of the box, so no additional add-on or extra to pay. What I'm demonstrating here is also available in the free trial.Calgary Loader
Impressed yet? I was considering the example above ran on my laptop - not an expensive server.Why might you use a Calgary database to store data?As a database manager or developer you may not have much need for another database tool, but as a line of business user then Calgary can be a very important way of speeding up analytical processes where these kind of large datasets are bei ng used and IT resources are either expensive or difficult to use. Who wants to wait weeks for specialist IT resource to build a database and design an index? You don't need to if you are using Alteryx because the tools are right in front of you and you can build a database quickly and easily without any development skills being needed. Clearly there is still a need for best practice around the management and use of Calgary files, but, in the right situation, I've used Calgary to devastating effect within Alteryx.Calgary comes with Alteryx out of the box, so no additional add-on or extra to pay. What I'm demonstrating here is also available in the free trial.Calgary Loader If you want to build a Calgary Database then this is the tool you'll start with. It's very simple to use, just flow into it the data you want to load and then specify the columns you want to index and where you want the Calgary database to sit on your file system. A Calgary database is simply a file with a .cydb extension, indexes will also appear in this location as separate files.Let's illustrate this by example using some Airlines data available online, looking at the delays of flights over several years, there's ~120 million records split into yearly csv downloadable from here: http://stat-computing.org/dataexpo/2009/the-data.html.Here's the module I used to create a Calgary database - you'll notice I've created a date field and some other fields and changed some field types, I'm also using the wildcard delimiter on the Input tool to import all the csv's at once. I'm indexing a few fields and importing all the data into Calgary.
If you want to build a Calgary Database then this is the tool you'll start with. It's very simple to use, just flow into it the data you want to load and then specify the columns you want to index and where you want the Calgary database to sit on your file system. A Calgary database is simply a file with a .cydb extension, indexes will also appear in this location as separate files.Let's illustrate this by example using some Airlines data available online, looking at the delays of flights over several years, there's ~120 million records split into yearly csv downloadable from here: http://stat-computing.org/dataexpo/2009/the-data.html.Here's the module I used to create a Calgary database - you'll notice I've created a date field and some other fields and changed some field types, I'm also using the wildcard delimiter on the Input tool to import all the csv's at once. I'm indexing a few fields and importing all the data into Calgary.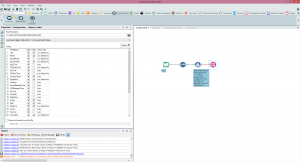
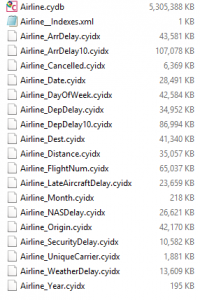 Running the module loads the data into Calgary and creates the necessary files (see pic on right). Once that's done (and you might want to wait loading csv data of this size from disk takes a while, on my laptop this module took 1hr 27 mins). The more indexes you add the longer it will take to create them (this is actually the majority of the time of the Calgary build process aside from loading the data from disk) and so you'll only want to index the fields you'll want to query. You can always build an index without reloading the data into Calgary by just pointing the loader tool at the existing file and deselecting the other index and data columns except for the Index for the field you want to index. Tip: the order of your Calgary file will help, presorting your file on the field you are most likely to query it on will massively speed up queries on that index.Once you've built your Calgary database the rest of the Calgary tools allow you to query it.Calgary Input
Running the module loads the data into Calgary and creates the necessary files (see pic on right). Once that's done (and you might want to wait loading csv data of this size from disk takes a while, on my laptop this module took 1hr 27 mins). The more indexes you add the longer it will take to create them (this is actually the majority of the time of the Calgary build process aside from loading the data from disk) and so you'll only want to index the fields you'll want to query. You can always build an index without reloading the data into Calgary by just pointing the loader tool at the existing file and deselecting the other index and data columns except for the Index for the field you want to index. Tip: the order of your Calgary file will help, presorting your file on the field you are most likely to query it on will massively speed up queries on that index.Once you've built your Calgary database the rest of the Calgary tools allow you to query it.Calgary Input The Calgary input tool is one way of accessing the raw records back from a Calgary database, generally by building a query on the records. So for example we can point the Calgary Input at our Calgary database and query flights on a certain date, see the screenshot below. Running this query queries the records in under a second (wow!), and returns the 13,396 records we want, these can then be used further down the data flow for further analysis.
The Calgary input tool is one way of accessing the raw records back from a Calgary database, generally by building a query on the records. So for example we can point the Calgary Input at our Calgary database and query flights on a certain date, see the screenshot below. Running this query queries the records in under a second (wow!), and returns the 13,396 records we want, these can then be used further down the data flow for further analysis.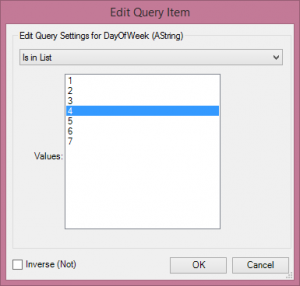 Calgary Join
Calgary Join This tool is not about joining Calgary databases together, rather it extends the functionality we just saw in the Calgary Input tool by allowing dynamic input to be queries, i.e. joining your data to the Calgary database In this way in our example we can bring in, say, a set of flight numbers from our dataflow and then use the data to pull all corresponding flight records from Calgary. I've also used this before for querying customer records, bringing them out of a Calgary database indexed on CustomerID.There are also several options for matching the data into Calgary and either appending the results, or getting data that matches ANY row, or every row. The example below shows me linking the UniqueCarrier field I've found from a Calgary Input (Carriers that were cancelled on Mondays in 1996) and using that as an input into a Calgary Join to find all the instances of those UniqueCarriers in the data (i.e. find all the flights those carriers made on Mondays in 1996).
This tool is not about joining Calgary databases together, rather it extends the functionality we just saw in the Calgary Input tool by allowing dynamic input to be queries, i.e. joining your data to the Calgary database In this way in our example we can bring in, say, a set of flight numbers from our dataflow and then use the data to pull all corresponding flight records from Calgary. I've also used this before for querying customer records, bringing them out of a Calgary database indexed on CustomerID.There are also several options for matching the data into Calgary and either appending the results, or getting data that matches ANY row, or every row. The example below shows me linking the UniqueCarrier field I've found from a Calgary Input (Carriers that were cancelled on Mondays in 1996) and using that as an input into a Calgary Join to find all the instances of those UniqueCarriers in the data (i.e. find all the flights those carriers made on Mondays in 1996).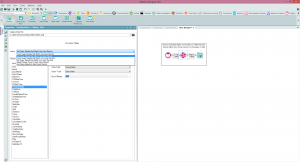 One of the things to be aware of is when the performance of a Calgary Join will be optimal. Calgary is optimal at record level searches for random records, I certainly would use it for querying on a few thousand records to tens of thousands, performance will degrade the less selective your query is, to the point that a normal join will be much quicker (you can use a Calgary file in a standard Input Tool to bring in the whole dataset). This is because of the indexing strategy used - to put it very simply (perhaps at the risk of oversimplification) Calgary join will do a record searches one at a time based on the index (quicker for lower record counts that are selective), Standard Join will do a sort and merge (quicker for less selective and higher record counts).Cross Count
One of the things to be aware of is when the performance of a Calgary Join will be optimal. Calgary is optimal at record level searches for random records, I certainly would use it for querying on a few thousand records to tens of thousands, performance will degrade the less selective your query is, to the point that a normal join will be much quicker (you can use a Calgary file in a standard Input Tool to bring in the whole dataset). This is because of the indexing strategy used - to put it very simply (perhaps at the risk of oversimplification) Calgary join will do a record searches one at a time based on the index (quicker for lower record counts that are selective), Standard Join will do a sort and merge (quicker for less selective and higher record counts).Cross Count The Cross Count tool essentially allows us to do a multidimensional crosstab on the fields in our Calgary database (and specify a query to filter the data before hand if we like). So in our example if we want to see the total numbers of flights by cancellation flag split by days of the week we would do it in this tool. This query takes 0.9 seconds to run for 123 million records - see below.
The Cross Count tool essentially allows us to do a multidimensional crosstab on the fields in our Calgary database (and specify a query to filter the data before hand if we like). So in our example if we want to see the total numbers of flights by cancellation flag split by days of the week we would do it in this tool. This query takes 0.9 seconds to run for 123 million records - see below.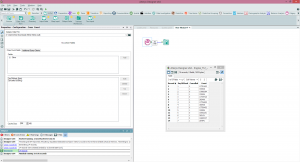 Cross Count Append
Cross Count Append If we want to do Cross Counts based on data within our dataflow then Cross Count append is our tool of choice. e.g if we had a list of flight numbers in our module and wanted to find the above crosstab (cancellations split by days of the week) just for those flights then we could do it within this tool (see below).
If we want to do Cross Counts based on data within our dataflow then Cross Count append is our tool of choice. e.g if we had a list of flight numbers in our module and wanted to find the above crosstab (cancellations split by days of the week) just for those flights then we could do it within this tool (see below).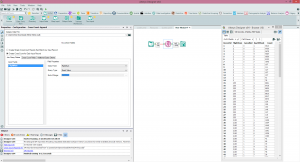 Extra CapabilitiesCalgary Databases can be linked (see Alteryx help files) to allow key based lookups across several databases (e.g. Customer Database to Transaction Database), this can further extend their functionality.Spatially Calgary can also be very advantageous, SpatialObjs (points) can be indexed and then used in queries on Polygons - so we can quickly query millions of records and find which ones are within a polygon or catchment within just a few seconds.ExamplesI've shared the Calgary database and modules from this example (with a smaller, 5m record sample version of the Calgary database so you don't have to download the massive database). You can find the modules here - https://www.dropbox.com/s/246bo7dj8ipmfj5/Calgary.zip giving you the opportunity to experiment with Calgary yourself, use the Free Alteryx Trial if needed.
Extra CapabilitiesCalgary Databases can be linked (see Alteryx help files) to allow key based lookups across several databases (e.g. Customer Database to Transaction Database), this can further extend their functionality.Spatially Calgary can also be very advantageous, SpatialObjs (points) can be indexed and then used in queries on Polygons - so we can quickly query millions of records and find which ones are within a polygon or catchment within just a few seconds.ExamplesI've shared the Calgary database and modules from this example (with a smaller, 5m record sample version of the Calgary database so you don't have to download the massive database). You can find the modules here - https://www.dropbox.com/s/246bo7dj8ipmfj5/Calgary.zip giving you the opportunity to experiment with Calgary yourself, use the Free Alteryx Trial if needed.
Impressed yet? I was considering the example above ran on my laptop - not an expensive server.Why might you use a Calgary database to store data?As a database manager or developer you may not have much need for another database tool, but as a line of business user then Calgary can be a very important way of speeding up analytical processes where these kind of large datasets are bei ng used and IT resources are either expensive or difficult to use. Who wants to wait weeks for specialist IT resource to build a database and design an index? You don't need to if you are using Alteryx because the tools are right in front of you and you can build a database quickly and easily without any development skills being needed. Clearly there is still a need for best practice around the management and use of Calgary files, but, in the right situation, I've used Calgary to devastating effect within Alteryx.Calgary comes with Alteryx out of the box, so no additional add-on or extra to pay. What I'm demonstrating here is also available in the free trial.Calgary LoaderIf you want to build a Calgary Database then this is the tool you'll start with. It's very simple to use, just flow into it the data you want to load and then specify the columns you want to index and where you want the Calgary database to sit on your file system. A Calgary database is simply a file with a .cydb extension, indexes will also appear in this location as separate files.Let's illustrate this by example using some Airlines data available online, looking at the delays of flights over several years, there's ~120 million records split into yearly csv downloadable from here: http://stat-computing.org/dataexpo/2009/the-data.html.Here's the module I used to create a Calgary database - you'll notice I've created a date field and some other fields and changed some field types, I'm also using the wildcard delimiter on the Input tool to import all the csv's at once. I'm indexing a few fields and importing all the data into Calgary.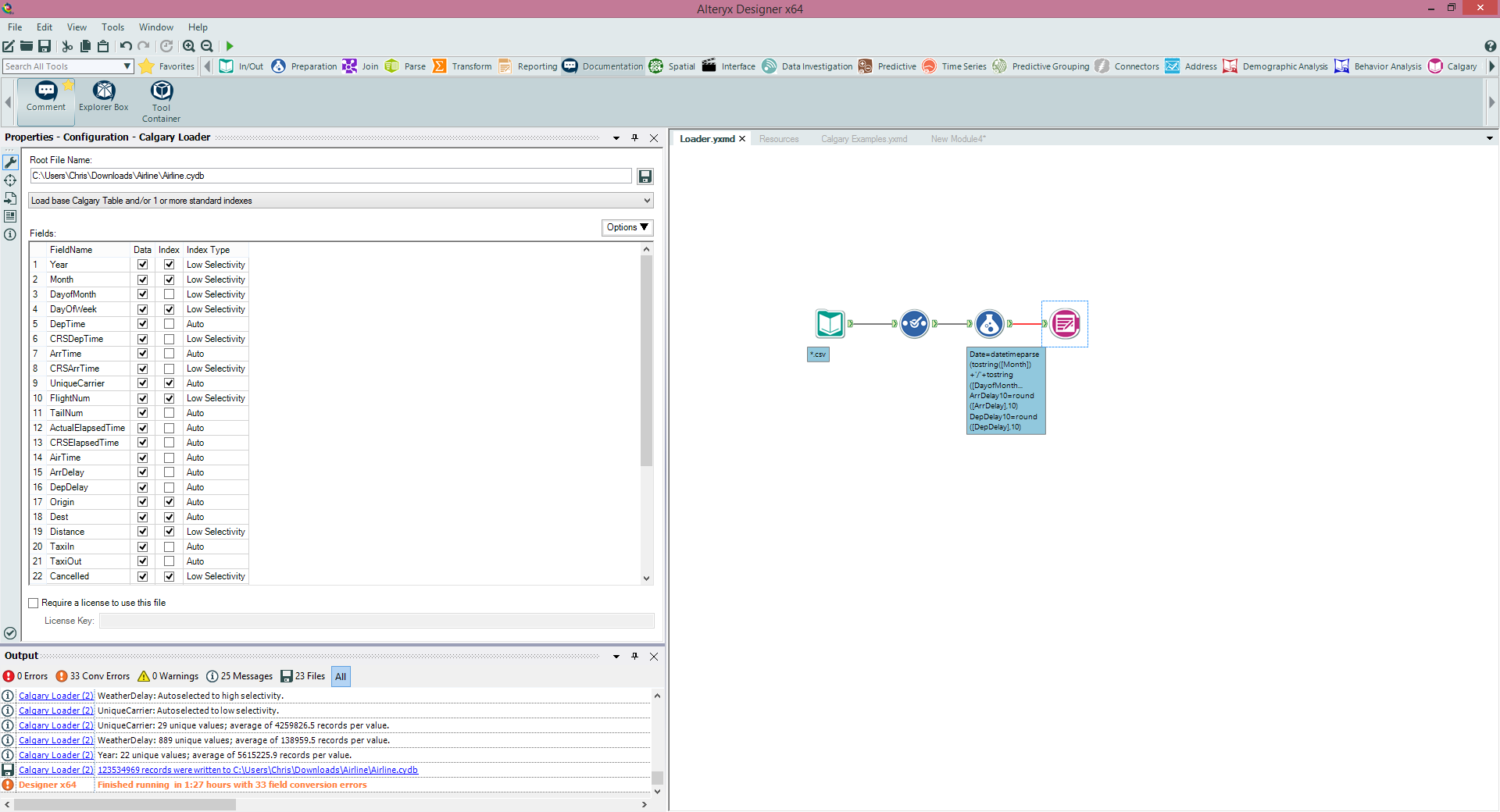 Running the module loads the data into Calgary and creates the necessary files (see pic on right). Once that's done (and you might want to wait loading csv data of this size from disk takes a while, on my laptop this module took 1hr 27 mins). The more indexes you add the longer it will take to create them (this is actually the majority of the time of the Calgary build process aside from loading the data from disk) and so you'll only want to index the fields you'll want to query. You can always build an index without reloading the data into Calgary by just pointing the loader tool at the existing file and deselecting the other index and data columns except for the Index for the field you want to index. Tip: the order of your Calgary file will help, presorting your file on the field you are most likely to query it on will massively speed up queries on that index.Once you've built your Calgary database the rest of the Calgary tools allow you to query it.Calgary InputThe Calgary input tool is one way of accessing the raw records back from a Calgary database, generally by building a query on the records. So for example we can point the Calgary Input at our Calgary database and query flights on a certain date, see the screenshot below. Running this query queries the records in under a second (wow!), and returns the 13,396 records we want, these can then be used further down the data flow for further analysis.
Running the module loads the data into Calgary and creates the necessary files (see pic on right). Once that's done (and you might want to wait loading csv data of this size from disk takes a while, on my laptop this module took 1hr 27 mins). The more indexes you add the longer it will take to create them (this is actually the majority of the time of the Calgary build process aside from loading the data from disk) and so you'll only want to index the fields you'll want to query. You can always build an index without reloading the data into Calgary by just pointing the loader tool at the existing file and deselecting the other index and data columns except for the Index for the field you want to index. Tip: the order of your Calgary file will help, presorting your file on the field you are most likely to query it on will massively speed up queries on that index.Once you've built your Calgary database the rest of the Calgary tools allow you to query it.Calgary InputThe Calgary input tool is one way of accessing the raw records back from a Calgary database, generally by building a query on the records. So for example we can point the Calgary Input at our Calgary database and query flights on a certain date, see the screenshot below. Running this query queries the records in under a second (wow!), and returns the 13,396 records we want, these can then be used further down the data flow for further analysis.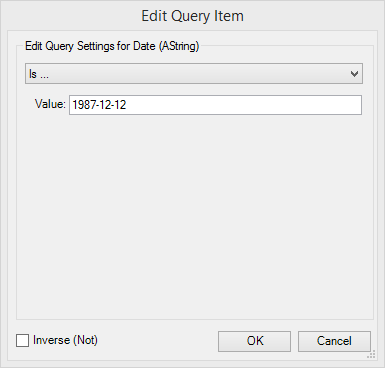
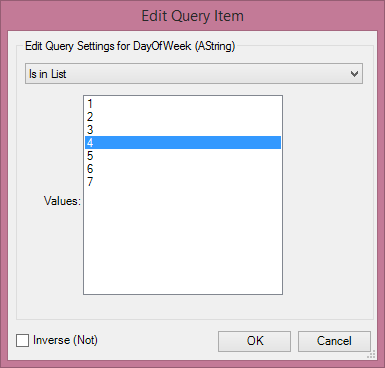 Calgary JoinThis tool is not about joining Calgary databases together, rather it extends the functionality we just saw in the Calgary Input tool by allowing dynamic input to be queries, i.e. joining your data to the Calgary database In this way in our example we can bring in, say, a set of flight numbers from our dataflow and then use the data to pull all corresponding flight records from Calgary. I've also used this before for querying customer records, bringing them out of a Calgary database indexed on CustomerID.There are also several options for matching the data into Calgary and either appending the results, or getting data that matches ANY row, or every row. The example below shows me linking the UniqueCarrier field I've found from a Calgary Input (Carriers that were cancelled on Mondays in 1996) and using that as an input into a Calgary Join to find all the instances of those UniqueCarriers in the data (i.e. find all the flights those carriers made on Mondays in 1996).
Calgary JoinThis tool is not about joining Calgary databases together, rather it extends the functionality we just saw in the Calgary Input tool by allowing dynamic input to be queries, i.e. joining your data to the Calgary database In this way in our example we can bring in, say, a set of flight numbers from our dataflow and then use the data to pull all corresponding flight records from Calgary. I've also used this before for querying customer records, bringing them out of a Calgary database indexed on CustomerID.There are also several options for matching the data into Calgary and either appending the results, or getting data that matches ANY row, or every row. The example below shows me linking the UniqueCarrier field I've found from a Calgary Input (Carriers that were cancelled on Mondays in 1996) and using that as an input into a Calgary Join to find all the instances of those UniqueCarriers in the data (i.e. find all the flights those carriers made on Mondays in 1996).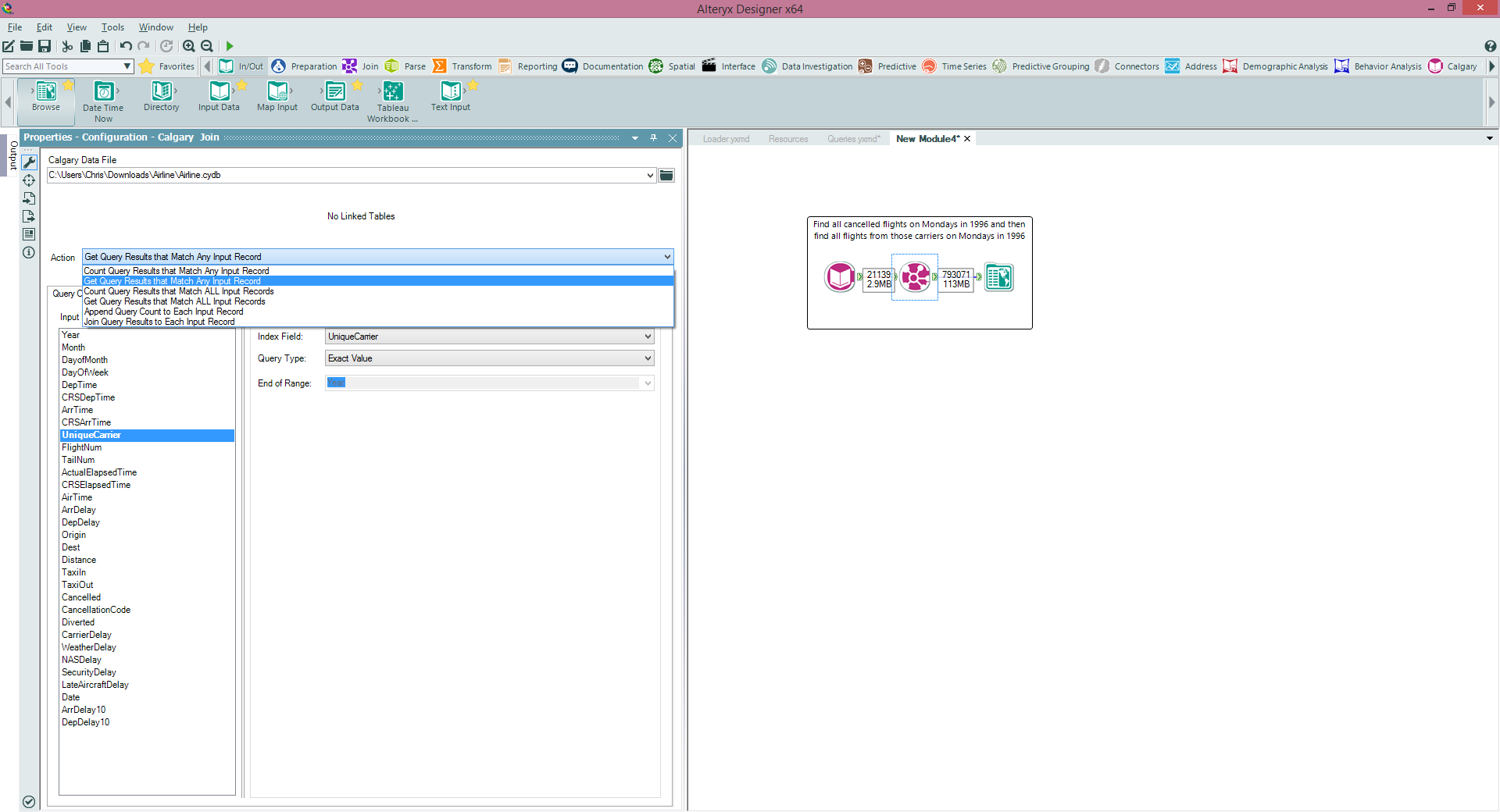 One of the things to be aware of is when the performance of a Calgary Join will be optimal. Calgary is optimal at record level searches for random records, I certainly would use it for querying on a few thousand records to tens of thousands, performance will degrade the less selective your query is, to the point that a normal join will be much quicker (you can use a Calgary file in a standard Input Tool to bring in the whole dataset). This is because of the indexing strategy used - to put it very simply (perhaps at the risk of oversimplification) Calgary join will do a record searches one at a time based on the index (quicker for lower record counts that are selective), Standard Join will do a sort and merge (quicker for less selective and higher record counts).Cross CountThe Cross Count tool essentially allows us to do a multidimensional crosstab on the fields in our Calgary database (and specify a query to filter the data before hand if we like). So in our example if we want to see the total numbers of flights by cancellation flag split by days of the week we would do it in this tool. This query takes 0.9 seconds to run for 123 million records - see below.
One of the things to be aware of is when the performance of a Calgary Join will be optimal. Calgary is optimal at record level searches for random records, I certainly would use it for querying on a few thousand records to tens of thousands, performance will degrade the less selective your query is, to the point that a normal join will be much quicker (you can use a Calgary file in a standard Input Tool to bring in the whole dataset). This is because of the indexing strategy used - to put it very simply (perhaps at the risk of oversimplification) Calgary join will do a record searches one at a time based on the index (quicker for lower record counts that are selective), Standard Join will do a sort and merge (quicker for less selective and higher record counts).Cross CountThe Cross Count tool essentially allows us to do a multidimensional crosstab on the fields in our Calgary database (and specify a query to filter the data before hand if we like). So in our example if we want to see the total numbers of flights by cancellation flag split by days of the week we would do it in this tool. This query takes 0.9 seconds to run for 123 million records - see below.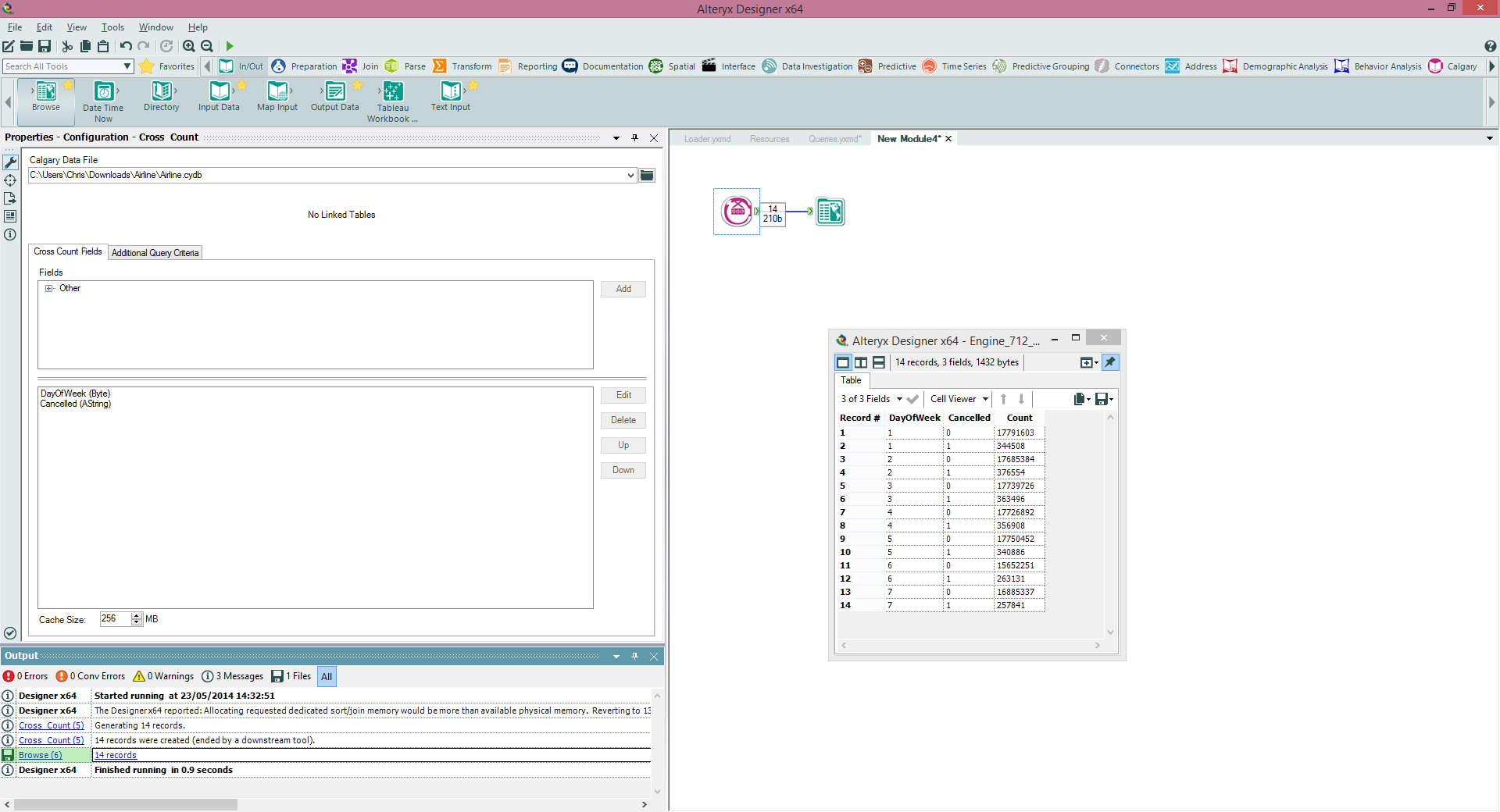 Cross Count AppendIf we want to do Cross Counts based on data within our dataflow then Cross Count append is our tool of choice. e.g if we had a list of flight numbers in our module and wanted to find the above crosstab (cancellations split by days of the week) just for those flights then we could do it within this tool (see below).
Cross Count AppendIf we want to do Cross Counts based on data within our dataflow then Cross Count append is our tool of choice. e.g if we had a list of flight numbers in our module and wanted to find the above crosstab (cancellations split by days of the week) just for those flights then we could do it within this tool (see below).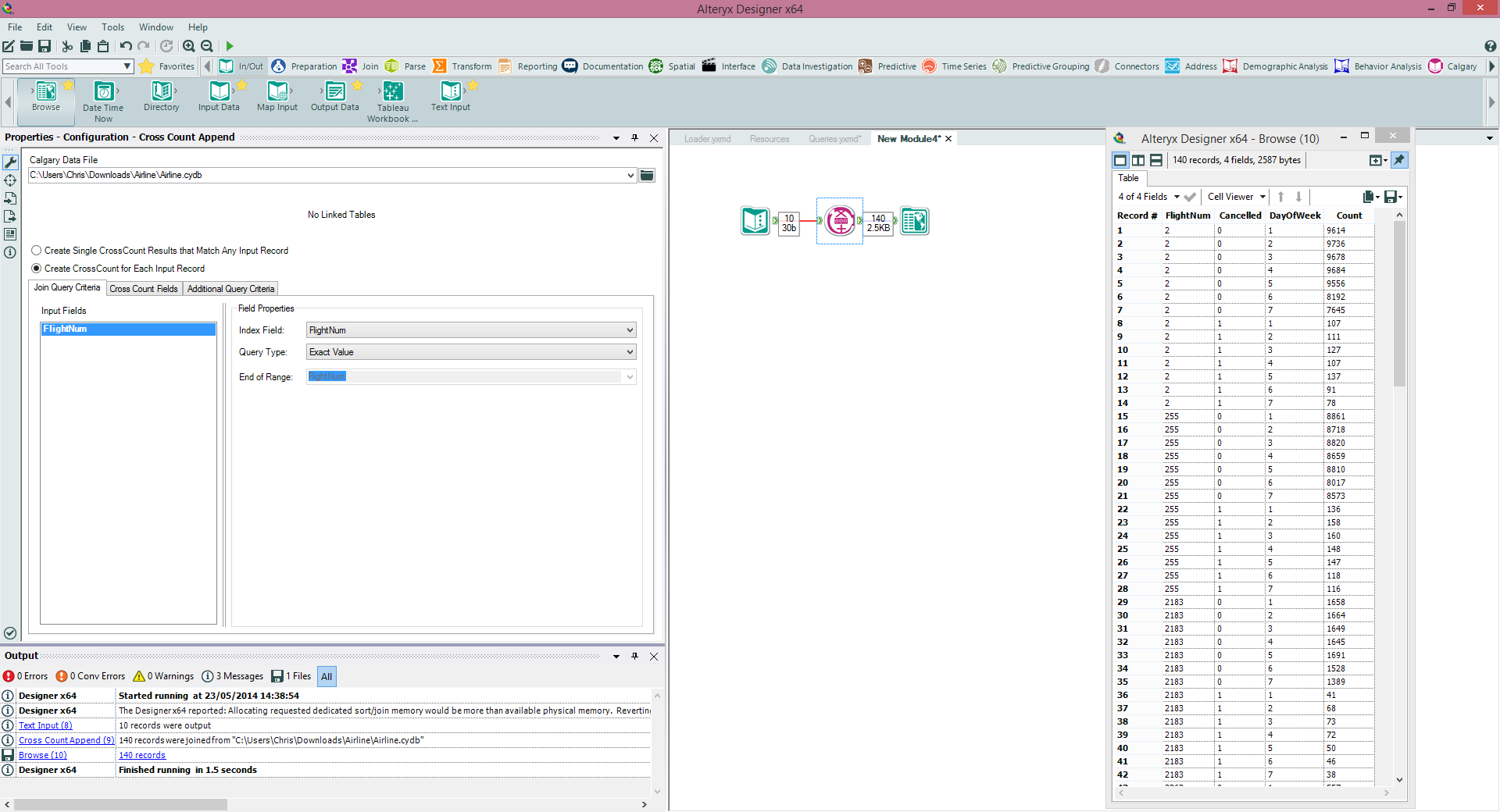 Extra CapabilitiesCalgary Databases can be linked (see Alteryx help files) to allow key based lookups across several databases (e.g. Customer Database to Transaction Database), this can further extend their functionality.Spatially Calgary can also be very advantageous, SpatialObjs (points) can be indexed and then used in queries on Polygons - so we can quickly query millions of records and find which ones are within a polygon or catchment within just a few seconds.ExamplesI've shared the Calgary database and modules from this example (with a smaller, 5m record sample version of the Calgary database so you don't have to download the massive database). You can find the modules here - https://www.dropbox.com/s/246bo7dj8ipmfj5/Calgary.zip giving you the opportunity to experiment with Calgary yourself, use the Free Alteryx Trial if needed.
Extra CapabilitiesCalgary Databases can be linked (see Alteryx help files) to allow key based lookups across several databases (e.g. Customer Database to Transaction Database), this can further extend their functionality.Spatially Calgary can also be very advantageous, SpatialObjs (points) can be indexed and then used in queries on Polygons - so we can quickly query millions of records and find which ones are within a polygon or catchment within just a few seconds.ExamplesI've shared the Calgary database and modules from this example (with a smaller, 5m record sample version of the Calgary database so you don't have to download the massive database). You can find the modules here - https://www.dropbox.com/s/246bo7dj8ipmfj5/Calgary.zip giving you the opportunity to experiment with Calgary yourself, use the Free Alteryx Trial if needed.