

Names and Values
These types of files come up many times for many reasons, in fact I came across a file similar to this when scraping my IronViz. Here's an example of a file: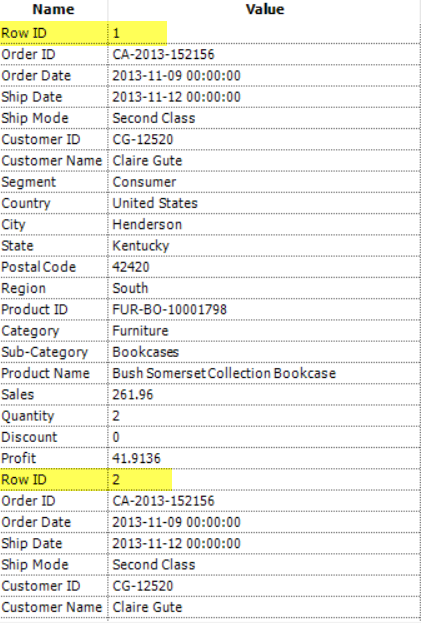 The key thing here to notice is that there are only two columns, and that the file order matters.So how do we solve this problem? Well the first step is to realise we will need to crosstab the data, but when we do that we need a 'key' to group on.The key will decide the rows for our data and so each group of rows needs the same key, like below:
The key thing here to notice is that there are only two columns, and that the file order matters.So how do we solve this problem? Well the first step is to realise we will need to crosstab the data, but when we do that we need a 'key' to group on.The key will decide the rows for our data and so each group of rows needs the same key, like below: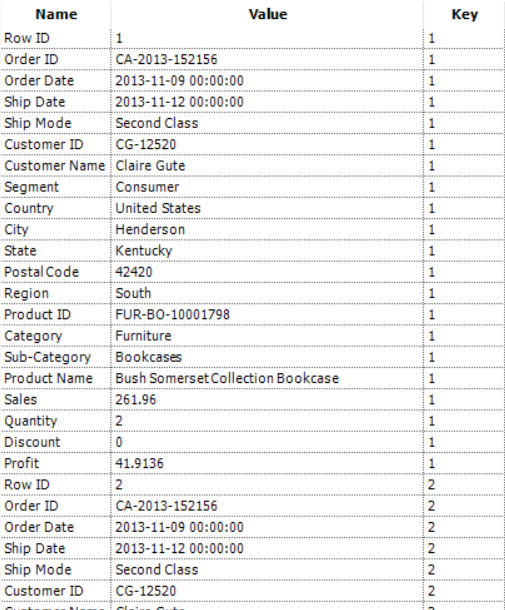
Adding a Key
To add a key as above we need to use a formula like this:if [Name] ='Row ID' then [Row-1:Key]+1 else [Row-1:Key] endifDoing this can't be done via the normal formula tool though as it doesn't support looking back or forward across multiple rows. Instead you need the Multi-Row Formula in the Preparation Category (don't confuse it with the Multi-Field formula which runs the same formula on multiple columns).
 The config should look like this:
The config should look like this: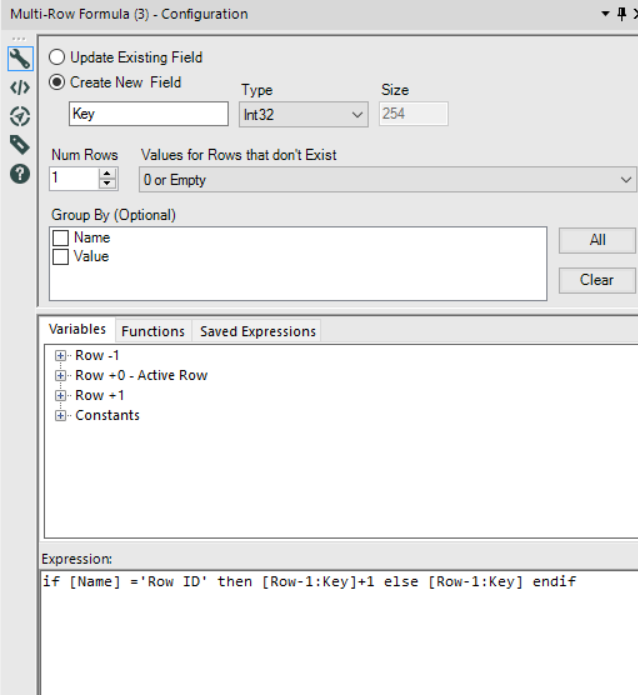
CrossTab
Now we simply need to crosstab the data, we need to Group by the Key - grouping creates a new row per field selected. The Name field will become our headers and the Value Field will be our data.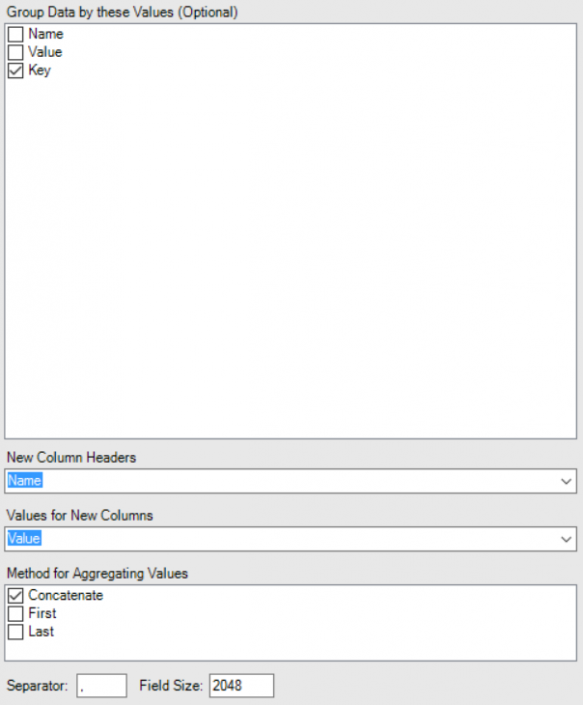 Which method do we use for Aggregating Values? The truth is it doesn't matter as we only have one value per Key / Name combination.The result:
Which method do we use for Aggregating Values? The truth is it doesn't matter as we only have one value per Key / Name combination.The result: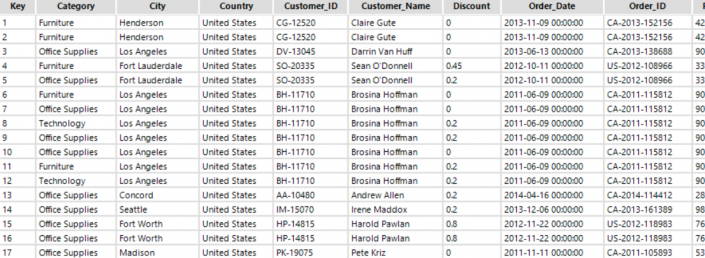 Finally let's fix our field types using the Auto Field tool, this clever tool will automatically select the correct field type.
Finally let's fix our field types using the Auto Field tool, this clever tool will automatically select the correct field type.Final Bonus Section
If you were astute you'll have noticed that the Crosstab Tool takes non-alphanumeric characters and turns them into an underscore in the Column Names. How do you fix this? Well first we need to know the old name and the new name...so let's use a formula tool on a branch of our original data set.....REGEX_Replace([Name], '[^A-Z0-9]', '_')
This formula will create what I call [CT Name] the new CrossTab field name.
Finally let's rename the strings using the Dynamic Rename tool to rename the Crosstabbed headers back to the originals using this new data stream. Your module should look like this I moved the Auto Field until after the grey Dynamic Rename - there's no reason for this except the messages from the Auto Field will refer to real field names now):
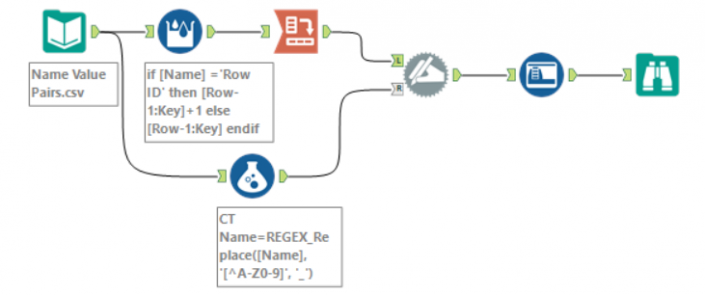
The Dynamic Rename replaces the Field Headers in its Left (Top) Input with the Data from the rows in its Right (Bottom) Input - so the config for that tool looks something like this:
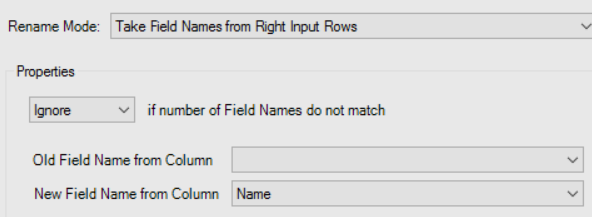
Note that I've chosen to 'Ignore' the number of Field Names not matching, I could easily have used a Unique tool to simply keep the distinct [Name].